For much of this year, I've been consulting at Open5G. The firm has ambitions to deliver high-speed internet access to millions of Americans. To do so, fiber-optic cables and antennas need to be deployed. This process is very capital-intensive we want to first deploy to the highest yielding locations within any target city or town.
Open5G has developed a model for this task using LocalSolver's Python API. It can take 20 different datasets and blend them together to help decide the best deployment route to take. Below is a figurative example of a roll-out plan rendered using Unfolded.
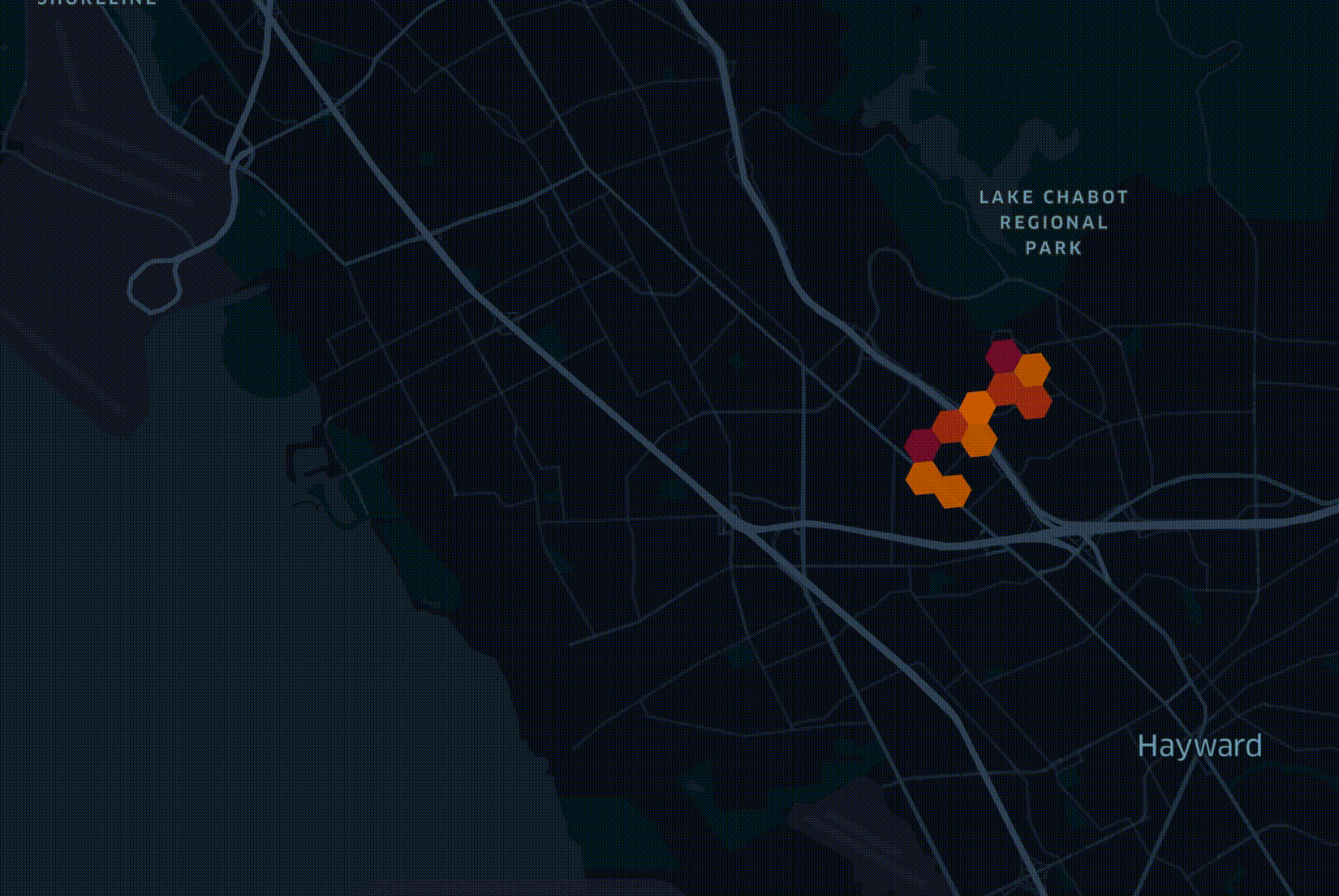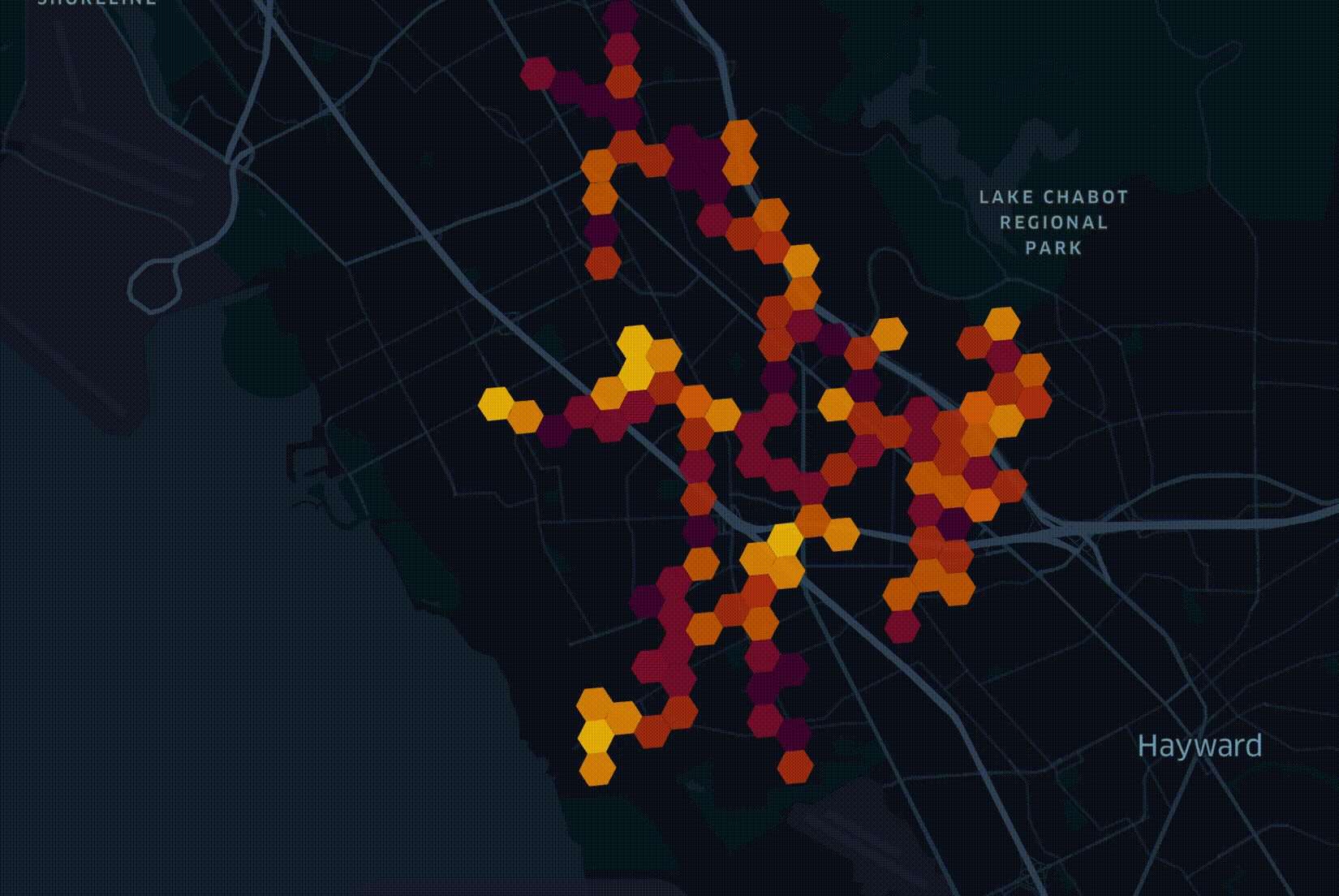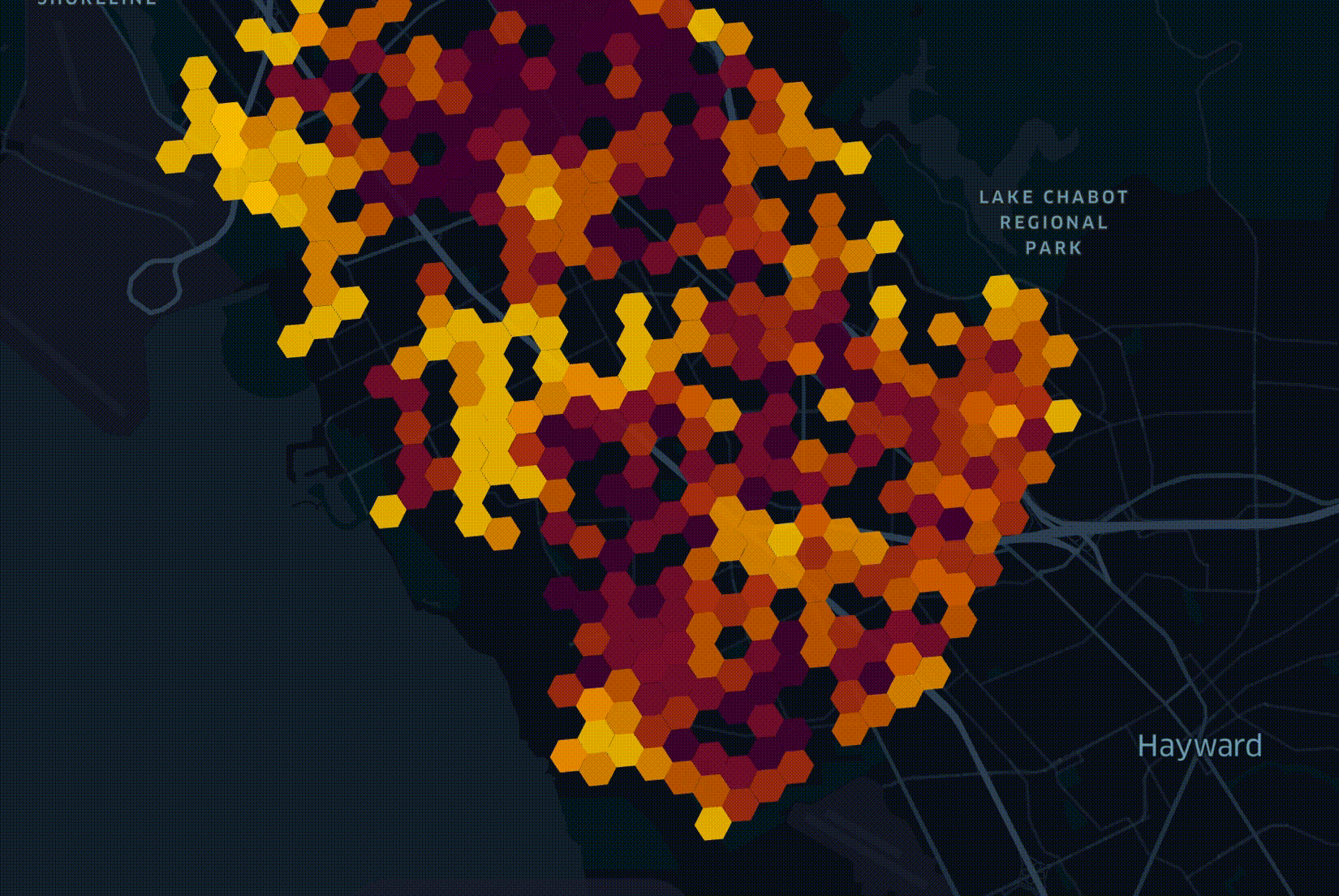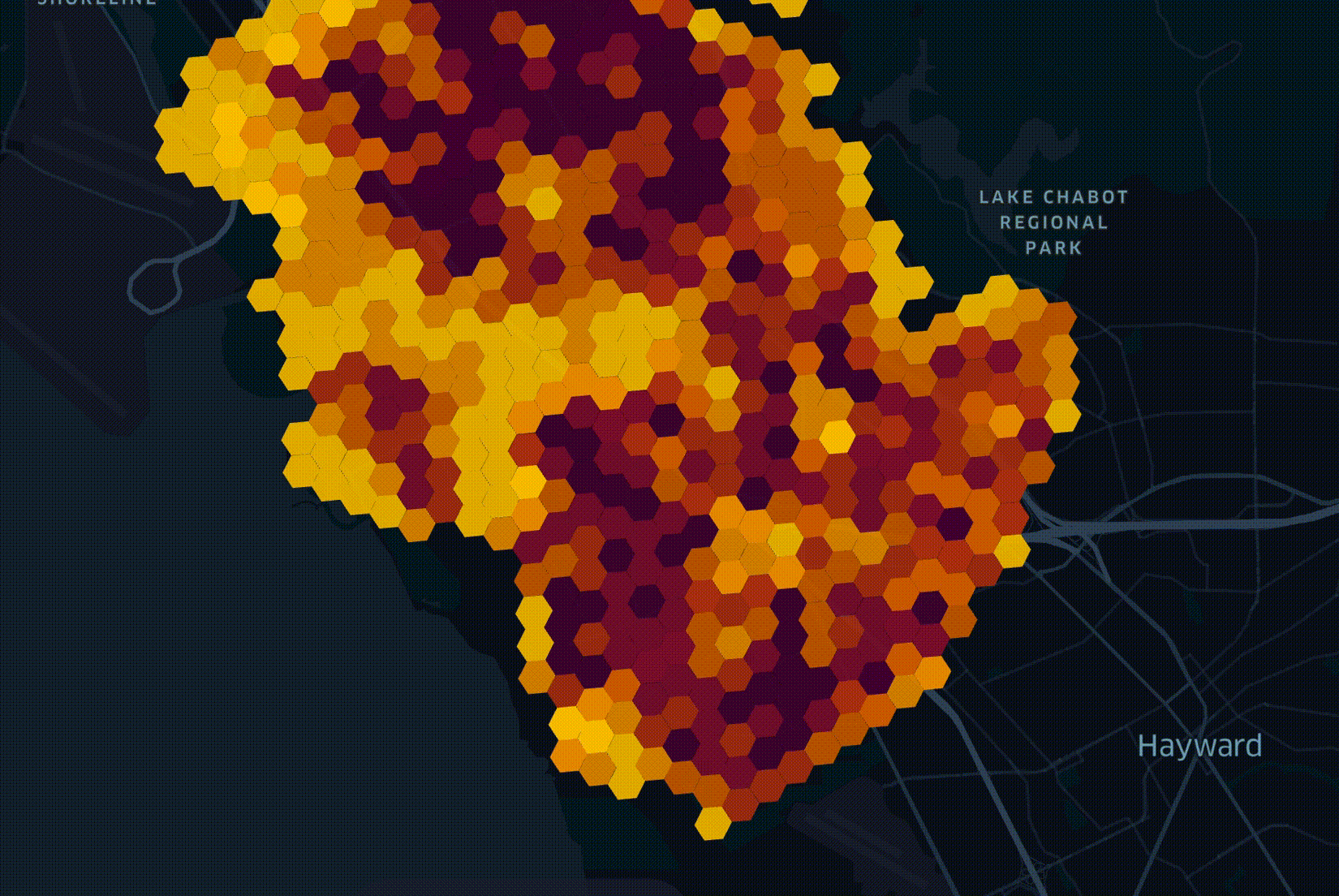
One of the considerations in deciding where to start deploying a network is how many trees are in a given geography. RF planning, underground trenching / boring and power pole attachment all need to take trees into account. My colleague Fabion Kauker, the CIO at Open5G, wrote software prior to joining which was used to design the national fiber networks for both New Zealand and Australia. On the New Zealand project, consideration for environmental impact meant routing cables around sacred trees.
In April researchers at the Swiss Federal Institute of Technology in Zurich published a global vegetation height map. It was put together by a convolutional neural network trained on a large cluster with both laser measurements from space as well as satellite imagery and supports a resolution of 10M2. The resulting dataset was released as a 359 GB set of 2,651 GeoTIFF files partitioned by latitude and longitude.
As with all geographic data at Open5G, records are grouped into hexagons in order to simplify each dataset and make it easy to join different datasets together. I cover this in greater detail in my Faster Geospatial Enrichment post. In this post, I'll walk through how we enriched and integrated ETH's global canopy dataset into our decision-making process for rolling out 5G across California.
A Large VM, Up & Running
I'm going to launch a n2-highmem-48 virtual machine instance in Google Cloud's Los Angeles region. The system will have 48 vCPUs, 384 GB of RAM and 1,500 GB of SSD-backed, pd-balanced storage capacity while running Ubuntu 20.04 LTS. This system would normally cost $3.27 / hour but as Open5G is a member of Google's Startups Cloud Program this cost was kindly absorbed by Google. Below is the GCP CLI command used to launch the VM.
$ gcloud compute instances create clickhouse \
--project=xxxx-nnnn \
--zone=us-west2-a \
--machine-type=n2-highmem-48 \
--network-interface=network-tier=PREMIUM,subnet=default \
--maintenance-policy=MIGRATE \
--provisioning-model=STANDARD \
--service-account=nnn-compute@developer.gserviceaccount.com \
--scopes=https://www.googleapis.com/auth/devstorage.read_only,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/trace.append \
--create-disk=auto-delete=yes,boot=yes,device-name=clickhouse,image=projects/ubuntu-os-cloud/global/images/ubuntu-2004-focal-v20220419,mode=rw,size=1500,type=projects/xxxx-nnnn/zones/us-west2-a/diskTypes/pd-balanced \
--no-shielded-secure-boot \
--shielded-vtpm \
--shielded-integrity-monitoring \
--reservation-affinity=any
With the above launched I can SSH into the machine.
$ gcloud compute ssh \
--zone "us-west2-a" \
--project "xxxx-nnnn" \
"clickhouse"
I'll first install the dependencies used throughout this post.
$ sudo apt update
$ sudo apt install \
gdal-bin \
python3-pip \
python3-virtualenv
$ virtualenv ~/.trees
$ source ~/.trees/bin/activate
$ python -m pip install \
ipython \
requests
Fetching TIFFs of Interest
Below is the EXIF data from one of the TIFFs in the dataset. It shows the image is 36K pixels wide by 36K pixels tall, is in greyscale and compressed using LZW compression.
$ exiftool ETH_GlobalCanopyHeight_10m_2020_N33W114_Map.tif
ExifTool Version Number : 11.88
File Name : ETH_GlobalCanopyHeight_10m_2020_N33W114_Map.tif
Directory : .
File Size : 123 MB
File Modification Date/Time : 2022:01:20 20:26:42+00:00
File Access Date/Time : 2022:05:04 14:19:33+00:00
File Inode Change Date/Time : 2022:05:02 12:12:46+00:00
File Permissions : rw-rw-r--
File Type : TIFF
File Type Extension : tif
MIME Type : image/tiff
Exif Byte Order : Little-endian (Intel, II)
Image Width : 36000
Image Height : 36000
Bits Per Sample : 8
Compression : LZW
Photometric Interpretation : BlackIsZero
Samples Per Pixel : 1
Planar Configuration : Chunky
Pixel Scale : 8.33333333333333e-05 8.33333333333333e-05 0
Model Tie Point : 0 0 0 -114 36 0
Subfile Type : Reduced-resolution image
Predictor : Horizontal differencing
Tile Width : 1024
Tile Length : 1024
Tile Offsets : 15618
Tile Byte Counts : 71357
Sample Format : Unsigned
GDAL No Data : 255
Geo Tiff Version : 1.1.0
GT Model Type : Geographic
GT Raster Type : Pixel Is Area
Geographic Type : WGS 84
Geog Citation : WGS 84
Geog Angular Units : Angular Degree
Geog Semi Major Axis : 6378137
Geog Inv Flattening : 298.257223563
Image Size : 36000x36000
Megapixels : 1296.0
The filename structure of the TIFFs indicates the geographic starting point of its partition. This saves the need to inspect the EXIF data of each file when determining which of the 2,651 candidate files are of interest.
I've built a Python script that will parse the filenames and if a name indicates it covers geography inside of a bounding box around California then it'll be downloaded, converted into a CSV using GDAL and compressed using GZIP.
The following script identified 15 files that overlap with California's boundaries.
$ ipython
import requests
url_stub = 'https://share.phys.ethz.ch/' \
'~pf/nlangdata/ETH_GlobalCanopyHeight_10m_2020_version1/3deg_cogs/'
resp = requests.get(url_stub)
lines = ['ETH' + x.split('.tif')[0].split('ETH')[-1] + '.tif'
for x in resp.text.splitlines()
if 'href="ETH_Global' in x
and '_SD' not in x]
cmds = []
workload = 'wget -c %(url_stub)s%(filename)s ' \
'&& gdal2xyz.py -csv %(filename)s N%(north)dW%(west)d.csv ' \
'&& gzip N%(north)dW%(west)d.csv'
for line in lines:
line = line.strip()
coords = line.split('2020_')[-1].split('_Map')[0].strip().upper()
if 'N' not in coords or 'W' not in coords:
continue
north, west = coords.lstrip('N').split('W')
north, west = int(north), int(west)
if north >= 32 and north <= 43 and west >= 114 and west <= 125:
cmds.append(workload % {'url_stub': url_stub,
'filename': line,
'north': north,
'west': west})
open('jobs', 'w').write('\n'.join(cmds))
The above produced a file containing chained BASH commands that I can execute in parallel. I'll open a screen and run a process for each TIFF. I can then type CTRL-A, CTRL-D and if I were to lose my SSH connection to the machine, the work will still continue to run in the background. I can reconnect to the screen by running screen -r at any time.
$ screen
$ cat jobs | xargs -n1 -P15 -I% bash -c "%"
The above took a little under 26 hours to complete. One of the files, which was a 123 MB TIFF was converted into a 1,296,000,000-line, 3.5 GB GZIP-compressed CSV file. Below is an extract of the first few lines of the resulting CSV.
$ gunzip -c N33W114.csv.gz | head
-113.9999583 35.99995833 0
-113.999875 35.99995833 0
-113.9997917 35.99995833 0
-113.9997083 35.99995833 0
-113.999625 35.99995833 0
-113.9995417 35.99995833 0
-113.9994583 35.99995833 0
-113.999375 35.99995833 0
-113.9992917 35.99995833 0
-113.9992083 35.99995833 0
There are a total of 20 billion rows across all 15 CSV files. This potentially puts the entire earth's dataset size at ~3.5 trillion records when in CSV format.
Enrich and Aggregate
I'm going to calculate the hexagons of each record for zoom levels 7 through 9 as well as calculate maximum, average, median, first and third quantile aggregates across the dataset. To do this, I'll first install ClickHouse and import the CSVs into it.
$ curl https://clickhouse.com/ | sh
$ sudo ./clickhouse install
$ sudo clickhouse start
$ clickhouse-client
CREATE TABLE eth_canopy1 (
x Float64,
y Float64,
z Float64)
ENGINE = Log();
Originally I planned to import the files in parallel but without tweaking the configuration I was left with clients timing out. I ended up setting the process count flag to 1.
$ ls N*W*.csv.gz \
| xargs -n1 \
-P1 \
-I% bash \
-c "gunzip -c % \
| sed 's/ /,/g' \
| clickhouse-client \
--query='INSERT INTO eth_canopy1 FORMAT CSV'"
The above produced a table that is 96 GB in size.
I found running a single SQL command that builds a table with multiple aggregates exhausted the system's available RAM. I decided to break up each aggregate's calculation into its own job and then merge the resulting tables. The following produced 15 SQL jobs.
$ ipython
sql = '''DROP TABLE IF EXISTS eth_canopy_h3_%(h3)d_%(name)s;
CREATE TABLE eth_canopy_h3_%(h3)d_%(name)s ENGINE = Log() AS
SELECT geoToH3(x, y, materialize(%(h3)d)) AS h3_%(h3)d,
%(funct)s AS %(name)s
FROM eth_canopy1
GROUP BY h3_%(h3)d;'''
cmds = []
for h3 in (7, 8, 9):
for name, funct in {'z_max': 'max(z)',
'z_avg': 'avg(z)',
'z_median': 'median(z)',
'z_q1': 'quantileExactLow(0.25)(z)',
'z_q3': 'quantileExactLow(0.75)(z)'}.items():
filename = '%d_%s.sql' % (h3, name)
open(filename, 'w').write(sql % {'h3': h3,
'name': name,
'funct': funct})
cmds.append('clickhouse-client --multiquery < %s' % filename)
open('jobs2', 'w').write('\n'.join(cmds))
I then tried to see how many jobs I could run at the same time. I eventually settled on running one at a time as one SQL command alone could consume ~60% of the compute capacity available and even running two at the same time created a lot of contention for the compute resources available.
$ screen
$ cat jobs2 | xargs -n1 -P1 -I% bash -c "%"
To compute the maximum aggregate for zoom level 7 took 3 hours and 5 minutes and produced a 254,280-record, 1.7 MB table.
I left the job to run overnight and the next day I ran the following to merge all of the tables together. The following only took a few moments to complete.
$ ipython
sql = '''
%(create_insert)s
SELECT %(h3)d AS h_level,
a.h3_%(h3)d AS h3,
a.z_max AS z_max,
b.z_avg AS z_avg,
c.z_median AS z_median,
d.z_q1 AS z_q1,
e.z_q3 AS z_q3
FROM eth_canopy_h3_%(h3)d_z_max a
LEFT JOIN eth_canopy_h3_%(h3)d_z_avg b ON a.h3_%(h3)d = b.h3_%(h3)d
LEFT JOIN eth_canopy_h3_%(h3)d_z_median c ON a.h3_%(h3)d = c.h3_%(h3)d
LEFT JOIN eth_canopy_h3_%(h3)d_z_q1 d ON a.h3_%(h3)d = d.h3_%(h3)d
LEFT JOIN eth_canopy_h3_%(h3)d_z_q3 e ON a.h3_%(h3)d = e.h3_%(h3)d;
'''
cmds = ['DROP TABLE IF EXISTS eth_canopy;']
for h3, create_insert in {
7: 'CREATE TABLE eth_canopy ENGINE = Log() AS',
8: 'INSERT INTO eth_canopy',
9: 'INSERT INTO eth_canopy'}.items():
cmds.append(sql % {'create_insert': create_insert, 'h3': h3})
open('run.sql', 'w').write('\n'.join(cmds))
$ clickhouse-client --multiquery < run.sql
Exporting the Data
I ran the following to export the resulting dataset into a GZIP-compressed CSV.
$ clickhouse-client \
--query "SELECT * FROM eth_canopy" \
--format CSV \
| gzip \
> eth_canopy.csv.gz
The above CSV contains 14,437,927 records and is 577 MB decompressed and 212 MB compressed. The following is an example record pulled later on from PostgreSQL.
\x
SELECT *
FROM eth_canopy
LIMIT 1;
h_level | 9
h3 | 617726166160113663
z_max | 255
z_avg | 27.32953181272509
z_median | 5
z_q1 | 4
z_q3 | 6
This is the breakdown of record counts by hexagon zoom level.
SELECT h_level,
COUNT(*)
FROM eth_canopy
GROUP BY h_level;
h_level | count
---------+----------
7 | 254280
8 | 1774697
9 | 12408950
Concluding Thoughts
I believe the TIFF to CSV conversion process could be sped up by splitting the calls to GDAL into four, one for each quadrant for each image. The width and height of each image is easy to determine and GDAL has a -srcwin xoff yoff xsize ysize flag already built-in so this might not take much effort.
I also suspect the above task might be well suited to a CUDA-based application running on an Nvidia GPU. The VM if left running would cost $2,385.61 / month as it is. If the whole planet were to be processed or if the dataset was updated more frequently then investment into this approach might pay off. The source imagery used by the neural network came from two satellites that photograph the entire earth every five days so more frequent processing isn't outside of the realms of possibility.
California has an area of 423,970 KM2 but the bounding box around it also covers parts of the Pacific Ocean and Nevada. A zoom level 7 hexagon should be around 5 KM2 and if the outline of California were perfectly respected 85K hexagons should be needed but 254K are produced with the above crude process. At some point using a polygon around California to cut out unused pixels would help reduce the amount of data ClickHouse ends up needing to process.
ClickHouse itself often has many ways a problem can be approached. I'm sure with a larger time box I could have made better use of the hardware available. There are a lot of leavers and knobs in its configuration file. If this post gathers enough attention I might post a follow up with any optimisations I can find.