Earlier this year I signed a consulting agreement with Open5G. Based in Atherton, California, the company builds and manages fiber-optic networks. At present, they have a handful of networks in the Bay Area but have plans to expand across the US.
The act of planning out how a fiber-optic network will be deployed across a city has many constraints to consider. The process is capital-intensive so you want the network to archive uptake as soon as possible. My team at Open5G builds network roll-out plans. This is done by blending over 20 data sources together and weighing their metrics against a number of business goals. The following is an illustrative example of a roll-out plan.
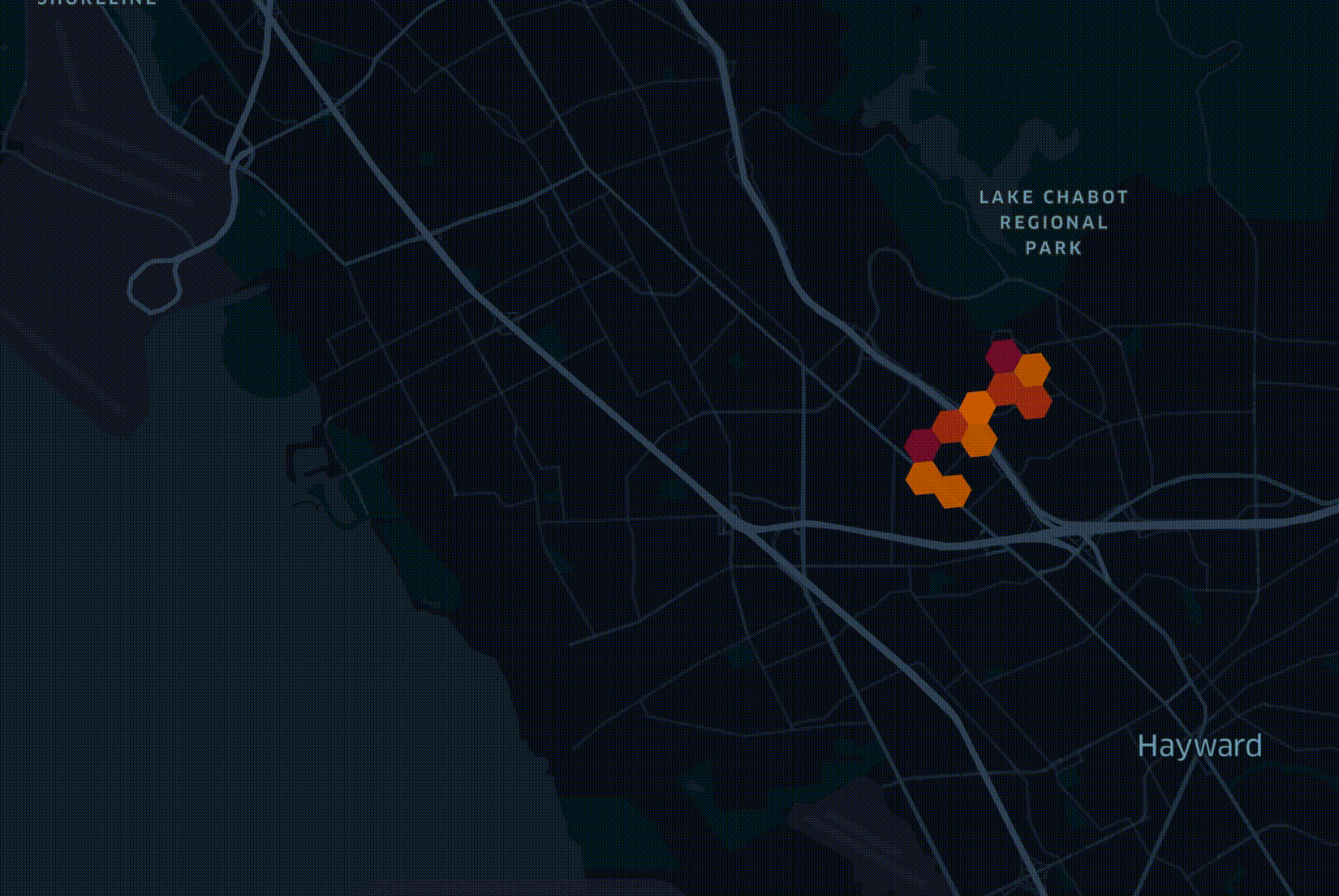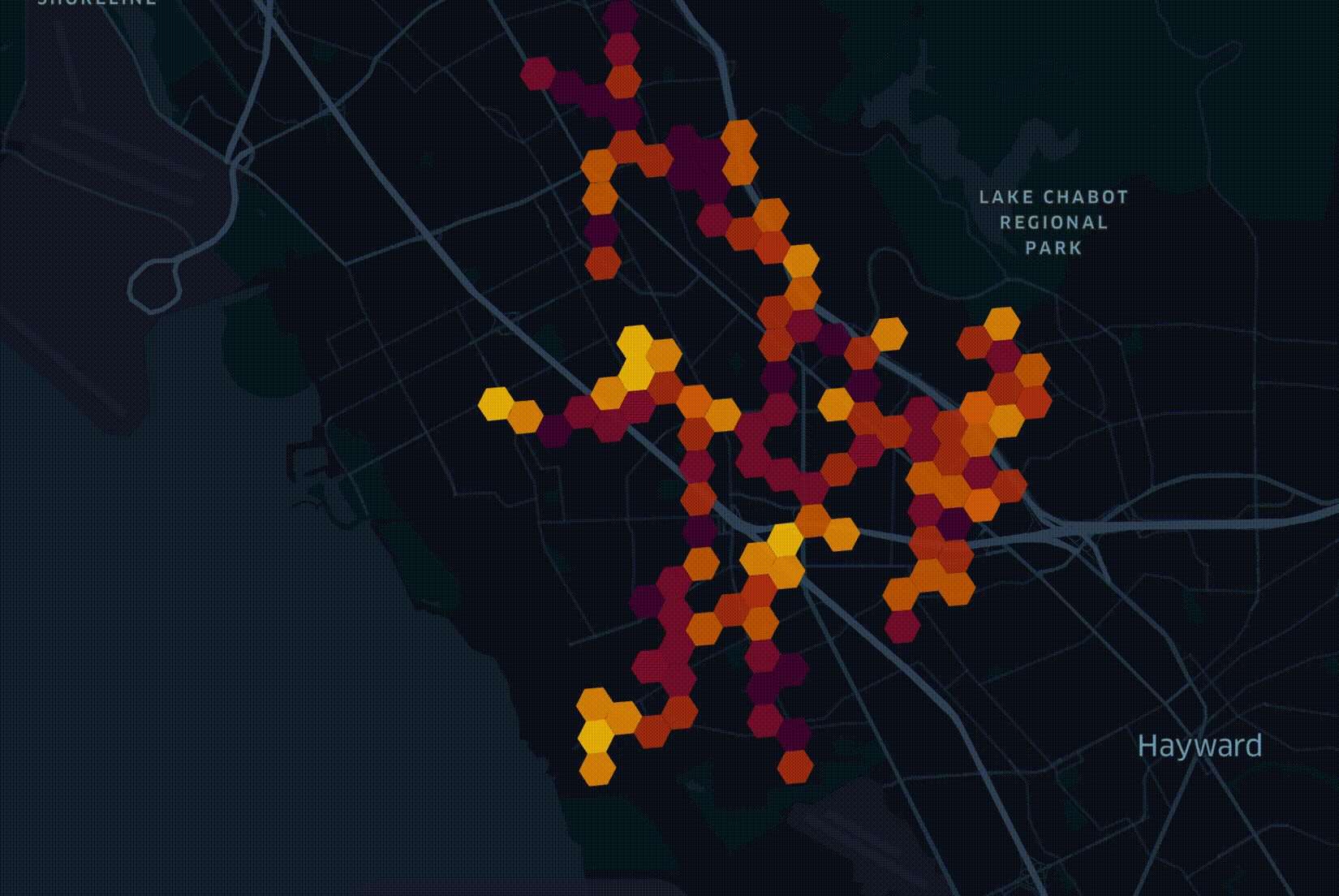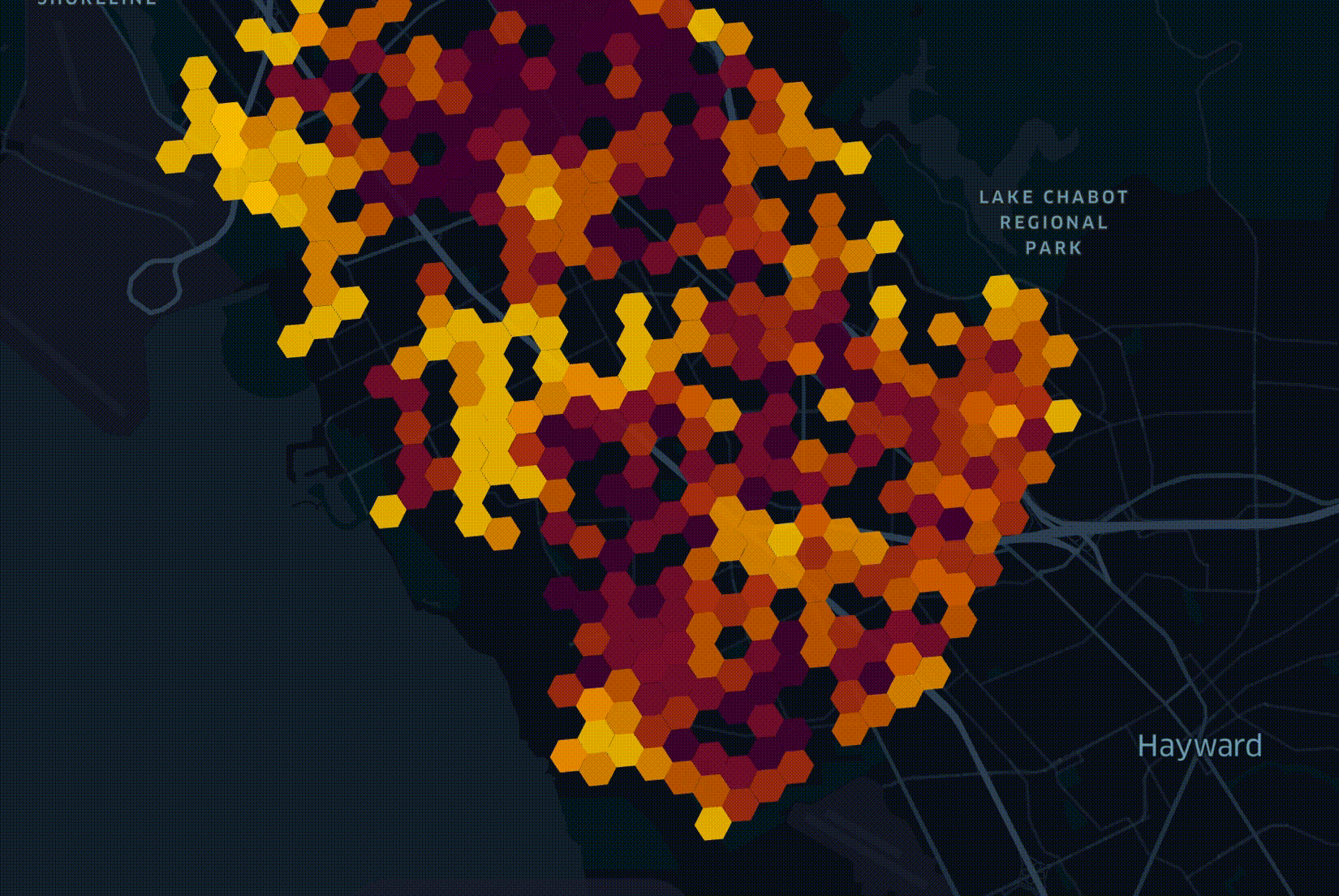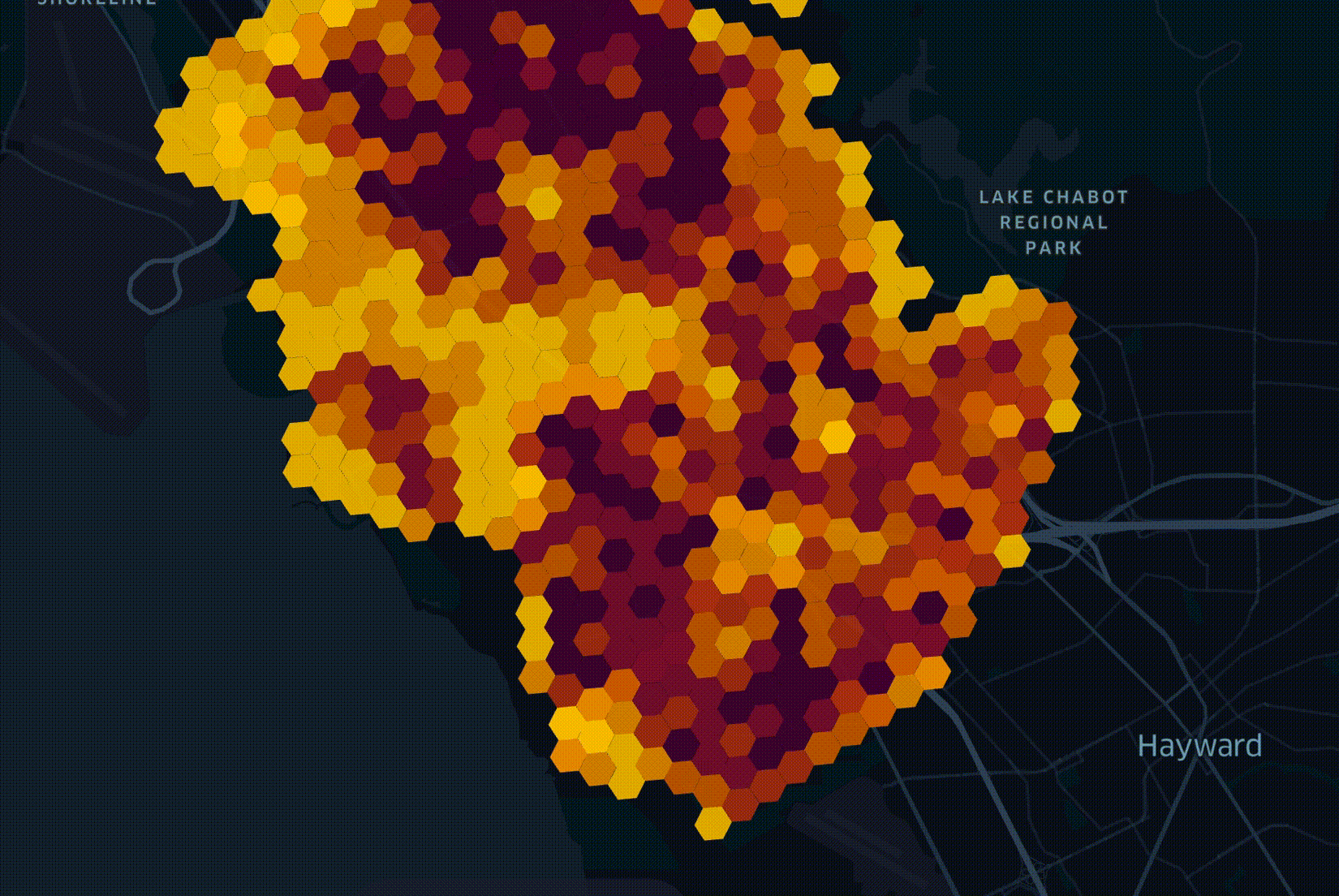
In the above visualisation, there is a hexagonal grid overlaid across a city. The hexagons appear in the order of fiber being deployed. Darker hexagons represent higher densities of potential customers. Several factors beyond projected revenue make up how a network is deployed. It's not as simple as the richest and most internet-deprived first.
The 20-odd datasets all contain latitude and longitude columns across every row of data. These are often either a single point or a polygon that is converted into a centroid. The points are then converted into groups of hexagons making them easier to aggregate. The following is an example conversion.
$ h3 latLngToCell \
--resolution 10 \
--latitude 40.689167 \
--longitude -74.044444
This is the resulting 64-bit identifier for the hexagon the above parameters fall into.
8a2a1072b59ffff
The hexagons we're using are from H3, Uber's Hexagonal Hierarchical Spatial Index, which was first publicly announced in 2018. This system uses a Gray-Fuller icosahedral projection of the Earth and lays out a series of hexagons on top of it. The use of this projection system means that any hexagon over land will suffer from a minimal amount of distortion and should generally keep its natural shape.
When zoomed out at level 0, a hexagon covers 4,250,546 km², a little more than half the size of Australia. At Zoom level 7, an area of ~5 km² will be filled by any individual hexagon. The 64-bit identifier for the hexagon at zoom level 0 that covers most of California is 8029fffffffffff. The more you zoom in, the fewer trailing Fs will be present in any given identifier. Matthias Feist, a Senior Engineering Manager at Spotify, built an excellent H3 exploration tool to help rationalise these identifiers over the surface of the Earth.
When converting latitude and longitude pairs into H3 identifiers, I found that different tools perform this task at very different rates. In this post, I'm going to benchmark PostgreSQL, ClickHouse and BigQuery against one another and see which can convert a set of coordinates into H3 identifiers the fastest.
PostgreSQL, Up & Running
I'll be using a virtual machine on Google Cloud. It's an e2-standard-4 with 4 vCPUs, 16 GB of RAM, 300 GB of SSD-backed, pd-balanced storage capacity running Ubuntu 20.04 LTS in their us-west2-a zone in Los Angeles, California.
The following will install some build tools, Python 3 and PostgreSQL 14 with the PostGIS extension.
$ wget -qO- \
https://www.postgresql.org/media/keys/ACCC4CF8.asc \
| sudo apt-key add -
$ echo "deb http://apt.postgresql.org/pub/repos/apt/ focal-pgdg main 14" \
| sudo tee /etc/apt/sources.list.d/pgdg.list
$ sudo apt update
$ sudo apt install \
build-essential \
python3-pip \
python3-virtualenv \
postgresql-14-postgis-3 \
postgresql-14-postgis-3-scripts \
postgresql-client-14 \
postgresql-server-dev-14 \
postgis
I'll then set up a user account with PostgreSQL.
$ sudo -u postgres \
bash -c "psql -c \"CREATE USER mark
WITH PASSWORD 'test'
SUPERUSER;\""
The following will set up PostGIS and then the h3db database I'll be using.
$ createdb template_postgis
$ psql -d postgres -c "UPDATE pg_database SET datistemplate='true' WHERE datname='template_postgis';"
$ psql template_postgis -c "create extension postgis"
$ psql template_postgis -c "create extension postgis_topology"
$ psql template_postgis -f /usr/share/postgresql/14/contrib/postgis-3.2/legacy.sql
$ psql -d template_postgis -c "GRANT ALL ON geometry_columns TO PUBLIC;"
$ psql -d template_postgis -c "GRANT ALL ON geography_columns TO PUBLIC;"
$ psql -d template_postgis -c "GRANT ALL ON spatial_ref_sys TO PUBLIC;"
$ createdb -T template_postgis h3db
Uber's H3 library requires at a minimum CMake v3.20 and Ubuntu 20 only ships with v3.16. Below I'll build and install version 3.20.
$ cd ~
$ wget -c https://github.com/Kitware/CMake/releases/download/v3.20.0/cmake-3.20.0.tar.gz
$ tar -xzf cmake-3.20.0.tar.gz
$ cd cmake-3.20.0
$ ./bootstrap --parallel=$(nproc)
$ make -j$(nproc)
$ sudo make install
The following will build Uber's H3 library. It was written primarily by Isaac Brodsky and David Ellis. It's made up of 13K lines of C code & headers.
$ git clone https://github.com/uber/h3 ~/h3
$ mkdir -p ~/h3/build
$ cd ~/h3/build
$ cmake ..
$ make -j$(nproc)
$ sudo make install
$ sudo ldconfig
I'll then build a PostgreSQL extension that adds support for H3. It was written by Zacharias Dyna Knudsen and is made up of 1,210 lines of C code and 1,237 lines of SQL.
$ git clone https://github.com/bytesandbrains/h3-pg ~/h3-pg
$ cd ~/h3-pg
$ make -j$(nproc)
$ sudo make install
I'll then set up the above extension in PostgreSQL.
$ psql h3db
CREATE EXTENSION h3;
SELECT H3_GEO_TO_H3(POINT(37.769377, -122.388903), 9);
The above should return the following:
h3_geo_to_h3
-----------------
89e35ad6d87ffff
Importing OpenCelliD
OpenCelliD is a community project that collects GPS positions and network coverage patterns from cell towers around the globe. They produce a 45M-record dataset that is refreshed daily. This dataset is delivered as a GZIP-compressed CSV file. Below I'll download and import the dataset into PostgreSQL. Please replace the token in the URL with your own if you want to try this as well.
$ cd ~
$ wget "https://opencellid.org/ocid/downloads?token=...&type=full&file=cell_towers.csv.gz"
$ gunzip cell_towers.csv.gz
$ psql h3db
CREATE TABLE open_cell_towers (
radio VARCHAR,
mcc INTEGER,
net INTEGER,
area INTEGER,
cell BIGINT,
unit INTEGER,
lon FLOAT,
lat FLOAT,
range INTEGER,
samples INTEGER,
changeable INTEGER,
created INTEGER,
updated INTEGER,
averageSignal INTEGER);
\copy open_cell_towers FROM 'cell_towers.csv' DELIMITER ',' CSV HEADER
The above imported 45,214,074 records in 2 minutes and 40 seconds and consumes ~3.8 GB in PostgreSQL's internal format. Here is an example of one of the records:
\x on
SELECT * FROM open_cell_towers LIMIT 1;
radio | UMTS
mcc | 262
net | 2
area | 801
cell | 86355
unit | 0
lon | 13.285512
lat | 52.522202
range | 1000
samples | 7
changeable | 1
created | 1282569574
updated | 1300155341
averagesignal | 0
I'm now going to add H3 identifiers for each record. I'll do this for zoom levels 7 - 9.
ALTER TABLE open_cell_towers
ADD COLUMN IF NOT EXISTS h3_7 VARCHAR(15);
UPDATE open_cell_towers
SET h3_7 = H3_GEO_TO_H3(POINT(lat, lon), 7);
ALTER TABLE open_cell_towers
ADD COLUMN IF NOT EXISTS h3_8 VARCHAR(15);
UPDATE open_cell_towers
SET h3_8 = H3_GEO_TO_H3(POINT(lat, lon), 8);
ALTER TABLE open_cell_towers
ADD COLUMN IF NOT EXISTS h3_9 VARCHAR(15);
UPDATE open_cell_towers
SET h3_9 = H3_GEO_TO_H3(POINT(lat, lon), 9);
The above was completed in 18 minutes and 3 seconds.
Since this post was originally published it was suggested to build a new table while running enrichment. The following out-performed the above by 2.1x completing in 8 minutes and 14 seconds.
CREATE TABLE test AS SELECT
radio,
mcc,
net,
area,
cell,
unit,
lon,
lat,
range,
samples,
changeable,
created,
updated,
averageSignal,
H3_GEO_TO_H3(POINT(lat, lon), 7) as h3_7,
H3_GEO_TO_H3(POINT(lat, lon), 8) as h3_8,
H3_GEO_TO_H3(POINT(lat, lon), 9) as h3_9
FROM open_cell_towers;
ClickHouse, Up & Running
ClickHouse is a database I've covered many times on this blog. It has always performed well in benchmarks I've run against it. The following will install ClickHouse version 22.2.2.1.
$ sudo apt-key adv \
--keyserver hkp://keyserver.ubuntu.com:80 \
--recv E0C56BD4
$ echo "deb http://repo.yandex.ru/clickhouse/deb/stable/ main/" \
| sudo tee /etc/apt/sources.list.d/clickhouse.list
$ sudo apt update
$ sudo apt install \
clickhouse-client \
clickhouse-server
The following will launch the server.
$ sudo service clickhouse-server start
The following will save the password I set for the server so it doesn't need to be typed in each time the client connects.
$ mkdir -p ~/.clickhouse-client
$ vi ~/.clickhouse-client/config.xml
<config>
<password>test</password>
</config>
I'll create a table that sources the cell tower dataset in PostgreSQL.
$ clickhouse-client
CREATE TABLE open_cell_towers (
radio String,
mcc Int32,
net Int32,
area Int32,
cell Int64,
unit Int32,
lon Float64,
lat Float64,
range Int32,
samples Int32,
changeable Int32,
created Int32,
updated Int32,
averagesignal Int32)
ENGINE = PostgreSQL('localhost:5432',
'h3db',
'open_cell_towers',
'mark',
'test');
I will then import the data from PostgreSQL into a Log Engine table. This means the data is now located in ClickHouse's local storage using one of its native formats.
CREATE TABLE open_cell_towers2 ENGINE = Log() AS
SELECT radio,
mcc,
net,
area,
cell,
unit,
lon,
lat,
range,
samples,
changeable,
created,
updated,
averagesignal
FROM open_cell_towers;
I can't add columns to an existing Log Engine table in ClickHouse so I'll create a new table and add the h3 identifiers during that process.
CREATE TABLE open_cell_towers3 ENGINE = Log() AS
SELECT *,
geoToH3(toFloat64(lat), toFloat64(lon), materialize(7)) AS h3_7,
geoToH3(toFloat64(lat), toFloat64(lon), materialize(8)) AS h3_8,
geoToH3(toFloat64(lat), toFloat64(lon), materialize(9)) AS h3_9
FROM open_cell_towers2;
The above was completed in 70 seconds and produced a table that is 1.8 GB in size. This is a little over 7x faster than what I saw with the fastest PostgreSQL method.
Benchmarking BigQuery
The following loaded the dataset into a US-based BigQuery table in 65 seconds.
$ bq load --autodetect \
geodata.h3speedtest \
~/cell_towers.csv
This is the resulting schema:
$ bq show geodata.h3speedtest
Last modified Schema Total Rows Total Bytes Expiration Time Partitioning Clustered Fields Labels
----------------- --------------------------- ------------ ------------- ------------ ------------------- ------------------ --------
19 Apr 13:52:44 |- radio: string 45214074 4949843619
|- mcc: integer
|- net: integer
|- area: integer
|- cell: integer
|- unit: integer
|- lon: float
|- lat: float
|- range: integer
|- samples: integer
|- changeable: integer
|- created: integer
|- updated: integer
|- averageSignal: integer
I then ran the following to add 3 columns to the table. It took less than 2 seconds to complete.
ALTER TABLE geodata.h3speedtest ADD COLUMN h3_7 STRING;
ALTER TABLE geodata.h3speedtest ADD COLUMN h3_8 STRING;
ALTER TABLE geodata.h3speedtest ADD COLUMN h3_9 STRING;
I've used CARTO's publicly available H3 library for BigQuery to perform the enrichment.
UPDATE geodata.h3speedtest
SET h3_7 = jslibs.h3.ST_H3(ST_GEOGPOINT(lon, lat), 7),
h3_8 = jslibs.h3.ST_H3(ST_GEOGPOINT(lon, lat), 8),
h3_9 = jslibs.h3.ST_H3(ST_GEOGPOINT(lon, lat), 9)
WHERE True;
The above was completed in 23 minutes and 9 seconds while processing 4.61 GB. This is 2.8x slower than PostgreSQL and 19.8x slower than ClickHouse.