For much of the past year, I have been working with Hexvarium. Based in Atherton, California, the company builds and manages fiber-optic networks. At present, they have a handful of networks in the Bay Area but have plans to expand across the US.
The act of planning out how a fiber-optic network will be deployed across a city has many constraints to consider. The process is capital-intensive so you want the network to archive uptake as soon as possible. My team builds optimal network roll-out plans. This is done by blending over 70 datasets together and weighing their metrics against a number of business goals. The following is an illustrative example of a roll-out plan.
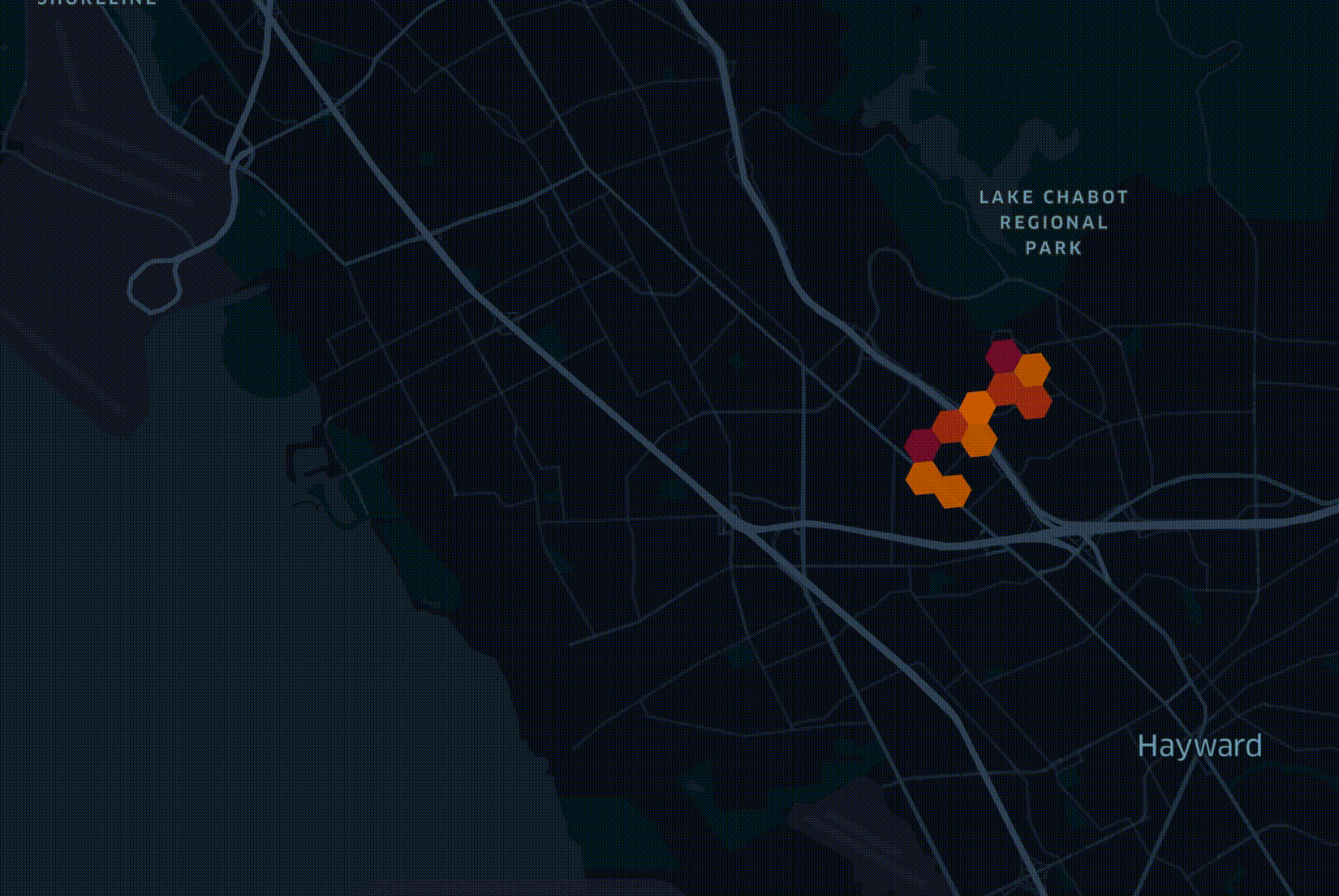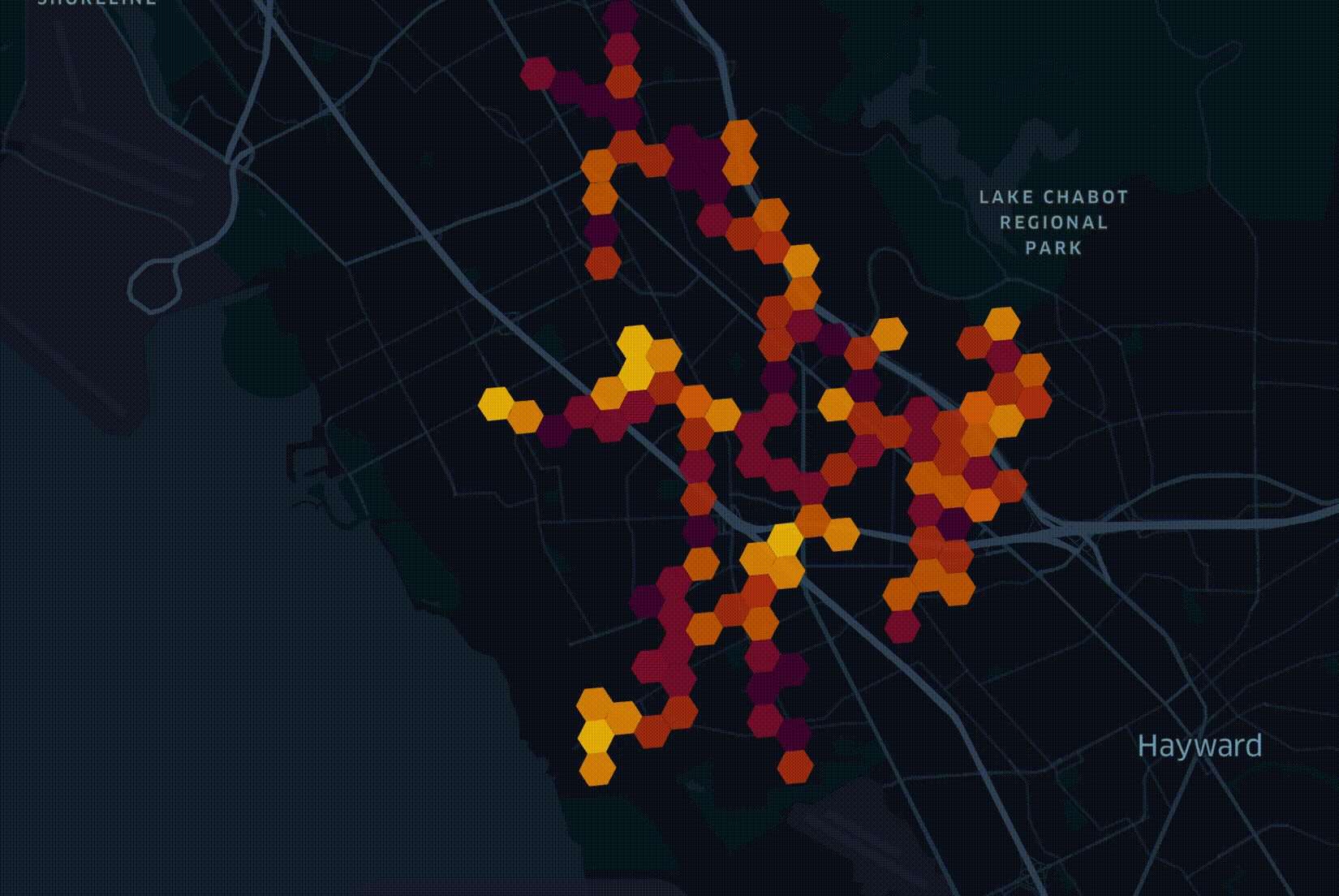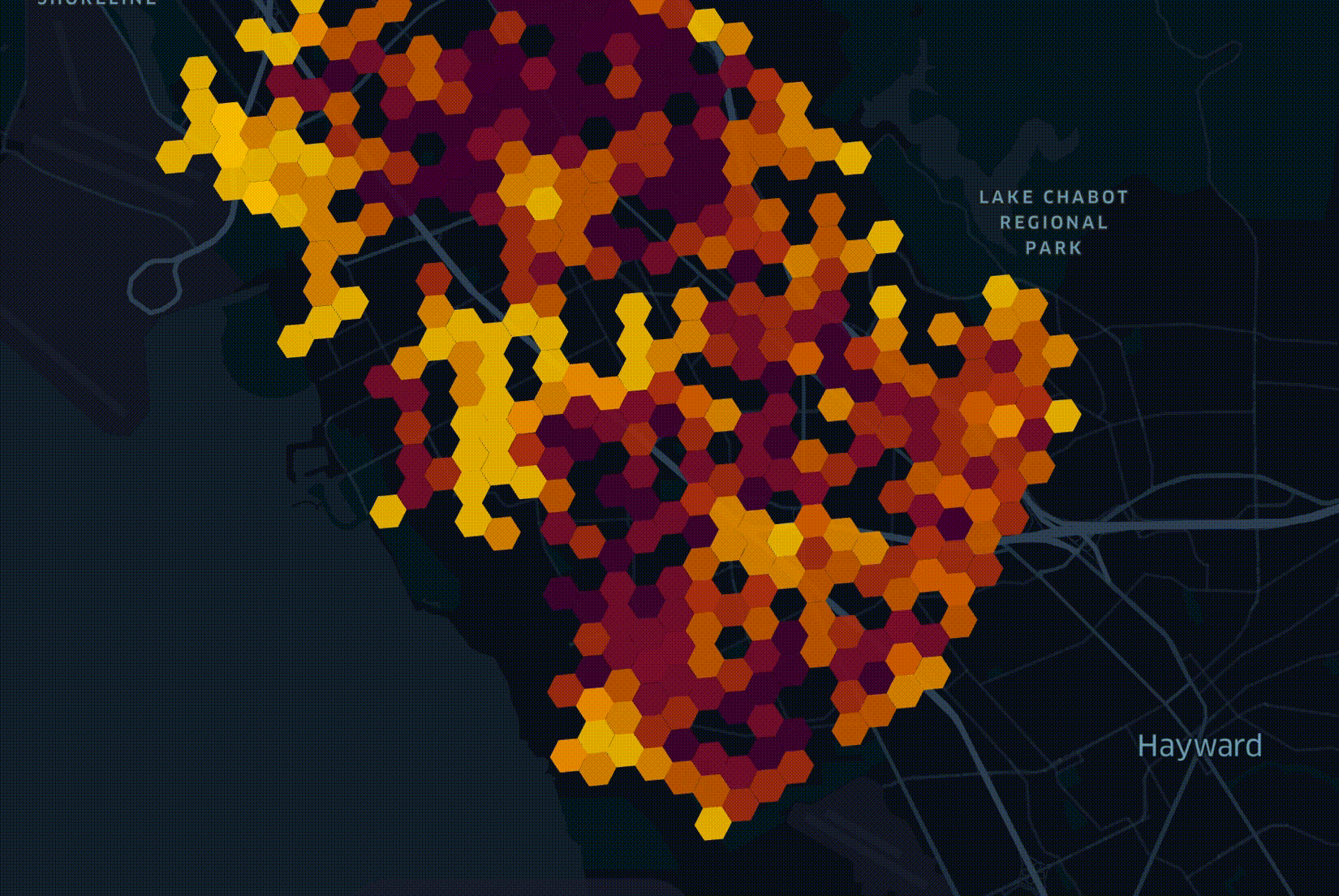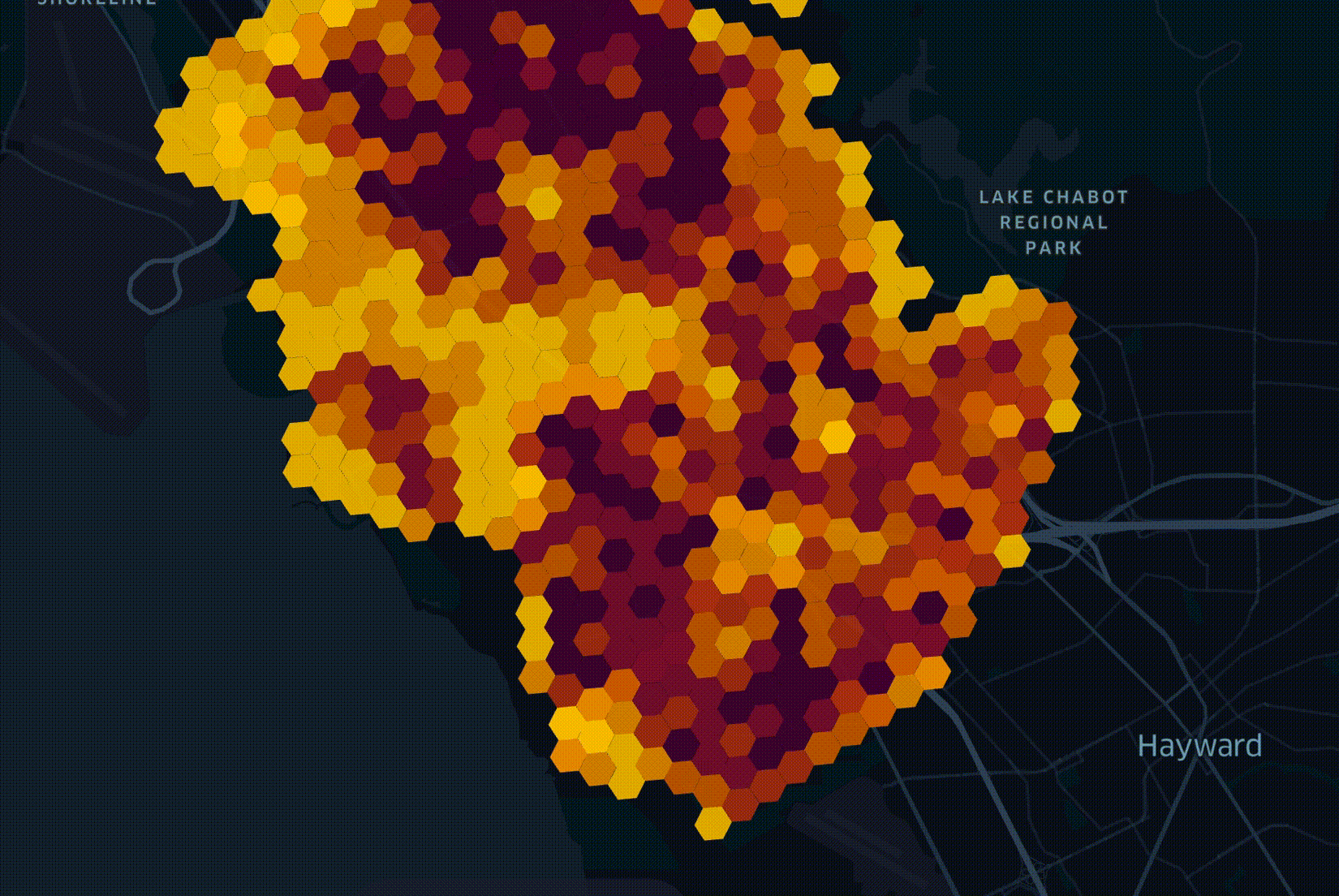
The above plans are produced by LocalSolver which is fed data from BigQuery. The majority of datasets we use arrive either in Esri's Geodatabase format or as Shapefiles, neither of which can be loaded into BigQuery directly. If a dataset is small enough or needs a lot of geospatial enrichments, we will load it into PostgreSQL with the PostGIS extension installed.
Below is a figurative example of a Geodatabase file being imported into PostgreSQL.
$ ogr2ogr --config PG_USE_COPY YES \
-f PGDump \
/vsistdout/ \
a00000001.gdbtable \
-lco SRID=4326 \
-lco SCHEMA=schema_name \
| psql geodata
If a dataset has 100M+ records and needs to be joined to another dataset with at least 10M+ records, then we'll load it into ClickHouse instead. ClickHouse has taken some of our JOINs that would take 2-3 days in PostgreSQL and completed them in under an hour. It can also scale up individual queries by simply adding more CPU cores. That said, ClickHouse lacks much of the geospatial functionality found in PostGIS so we cannot use it for all workloads.
Below is a figurative example of a Geodatabase file being imported into ClickHouse using GeoJSON as an intermediary format. To avoid timeouts, the JSONL file is produced first and then imported into ClickHouse rather than being streamed directly with a single BASH command.
$ ogr2ogr -f GeoJSONSeq \
/vsistdout/ \
-s_srs EPSG:4326 \
-t_srs EPSG:4326 \
a00000001.gdbtable \
| jq -S '.properties * {geom: .geometry}
| with_entries(.key |= ascii_downcase)' \
> out.jsonl
$ cat out.jsonl \
| clickhouse client \
--multiquery \
--query='SET input_format_skip_unknown_fields=1;
INSERT INTO table_name
FORMAT JSONEachRow'
In the past, I would dump PostgreSQL tables out to CSV files, compress them and then load them into BigQuery. But recently I've begun using ClickHouse to export PostgreSQL tables to Parquet and load that into BigQuery instead. This has resulted in faster load times.
In this post, I'll walk through one such example.
Installing Prerequisites
The VM used in this post is an e2-highcpu-32 with 32 vCPUs and 32 GB of RAM running Ubuntu 20.04 LTS. It is running in Google Cloud's us-west2-a region in Los Angeles. With a 400 GB balanced persistent disk, this system costs $1.02 / hour to run.
$ wget -qO- \
https://www.postgresql.org/media/keys/ACCC4CF8.asc \
| sudo apt-key add -
$ echo "deb http://apt.postgresql.org/pub/repos/apt/ focal-pgdg main 15" \
| sudo tee /etc/apt/sources.list.d/pgdg.list
$ sudo apt update
$ sudo apt install \
gdal-bin \
jq \
pigz \
postgresql-15 \
python3-pip \
python3-virtualenv
The commands used in this post are running on Ubuntu but they can also run on macOS. To install them via Homebrew run the following:
$ brew install \
gdal \
jq \
pigz \
postgresql \
virtualenv
I'll use PyArrow to examine a Parquet file at the end of this post.
$ virtualenv ~/.pq
$ source ~/.pq/bin/activate
$ python -m pip install \
pyarrow \
fastparquet \
shpyx
ClickHouse can be installed via the following:
$ curl https://clickhouse.com/ | sh
This post uses PostgreSQL 15 and ClickHouse v22.9.7.34. Both of these tools release new versions frequently.
I'll use Rustup to install Rust version 1.66.0.
$ curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
Google maintains installation notes for BigQuery's Python-based client.
The Buildings Dataset
Below is an example record from Microsoft's Buildings dataset. I've loaded it into PostgreSQL and enriched it with H3 hexagon values. It has 130,099,920 records, is 28 GB in PostgreSQL's internal format and takes up 61.6 GB of logical space once loaded into BigQuery.
$ psql geodata
\x on
SELECT *
FROM microsoft_buildings
LIMIT 1;
revision | 2
from_date | 2019-07-17
to_date | 2019-09-25
geom | 010200000005000000F148BC3C9DAB57C07BBE66B96C844340E6E8F17B9BAB57C0AB4203B16C844340FE2AC0779BAB57C02B85402E71844340098B8A389DAB57C0FC00A43671844340F148BC3C9DAB57C07BBE66B96C844340
h3_7 | 872656731ffffff
h3_8 | 8826567311fffff
h3_9 | 8926567311bffff
The geom column is in Well-known Binary (WKB) format. The above value can be expressed in GeoJSON as the following:
{"type": "LineString",
"coordinates":[[-94.681472, 39.034568],
[-94.681365, 39.034567],
[-94.681364, 39.034704],
[-94.681471, 39.034705],
[-94.681472, 39.034568]]}
The following shows a purple rendering of the above geometry with an OpenStreetMap basemap in QGIS.
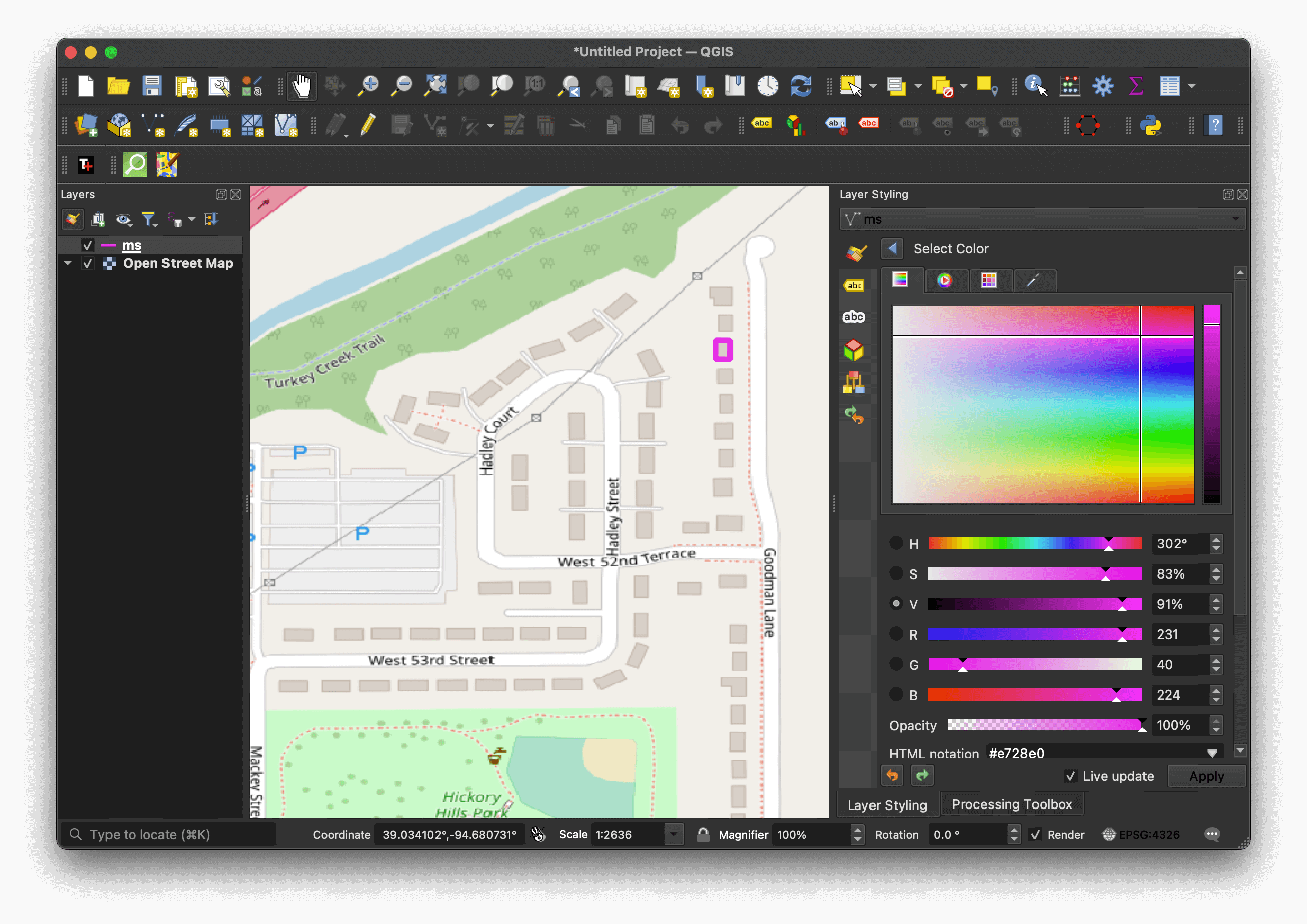
Transporting with CSV
The following will ship the above table from PostgreSQL to BigQuery using GZIP-compressed CSVs.
$ vi dump.sql
\copy (SELECT revision,
from_date,
to_date,
geom,
h3_7,
h3_8,
h3_9
FROM microsoft_buildings)
TO PROGRAM 'split --line-bytes=4000000000
--filter="pigz -1 > \$FILE.csv.gz"'
WITH CSV;
$ tr '\n' ' ' < dump.sql | psql geodata
The largest uncompressed CSV file size BigQuery will accept in a single load command is 4 GB. The above will break up the CSV data into separate files with no one file exceeding this limit. The CSV files are then compressed with the fastest setting GZIP supports. Higher compression settings have never resulted in faster end-to-end load times in my experience.
These are the resulting 12 GB of GZIP-compressed CSVs and their individual file sizes.
xaa.csv.gz 1.3 GB
xab.csv.gz 1.3 GB
xac.csv.gz 1.3 GB
xad.csv.gz 1.3 GB
xae.csv.gz 1.3 GB
xaf.csv.gz 1.3 GB
xag.csv.gz 1.3 GB
xah.csv.gz 1.3 GB
xai.csv.gz 1.3 GB
xaj.csv.gz 481 MB
The following will load the CSVs into BigQuery in parallel.
$ ls *.csv.gz \
| xargs -n1 \
-P10 \
-I% \
bash -c "bq load dataset.table_name ./% revision:INT64,from_date:DATE,to_date:DATE,geom:GEOGRAPHY,h3_7:STRING,h3_8:STRING,h3_9:STRING"
The above psql and bq load commands together took 18 minutes and 11 seconds to run.
Transporting with Parquet
The following will set up a table in ClickHouse that sources its data from the microsoft_buildings table in PostgreSQL.
$ clickhouse client
CREATE TABLE pg_ch_bq_microsoft_buildings (
revision Nullable(Int32),
from_date Nullable(DATE),
to_date Nullable(DATE),
geom Nullable(String),
h3_7 Nullable(String),
h3_8 Nullable(String),
h3_9 Nullable(String))
ENGINE = PostgreSQL('localhost:5432',
'airflow',
'microsoft_buildings',
'username',
'password');
I'll create a table that is local to ClickHouse. This avoids any more single-threaded fetches back to PostgreSQL later on.
CREATE TABLE microsoft_buildings ENGINE = Log() AS
SELECT *
FROM pg_ch_bq_microsoft_buildings;
I'll then create a script to dump the contents of the ClickHouse table across 14 Snappy-compressed Parquet files.
$ vi run.py
from multiprocessing import Pool
from shpyx import run as _exec
def ch(manifest):
offset, filename = manifest
sql = '''SELECT *
FROM microsoft_buildings
LIMIT 10000000
OFFSET %d
FORMAT Parquet''' % offset
cmd = "clickhouse client --query='%s' > %s" % \
(sql.replace('\n', ' '), filename)
print(cmd)
_exec(cmd)
payload = [(x * 10000000, 'out%s.pq' % str(x + 1))
for x in range(0, 14)]
pool = Pool(14)
pool.map(ch, payload)
I'll then run that script and load the resulting 16 GB of Parquet files into BigQuery.
$ python run.py
$ ls out*.pq \
| xargs -n1 \
-P14 \
-I% \
bash -c "bq load --source_format=PARQUET geodata.pq_test2 ./% revision:INT64,from_date:DATE,to_date:DATE,geom:GEOGRAPHY,h3_7:STRING,h3_8:STRING,h3_9:STRING"
The above took 14 minutes and 31 seconds to import, dump and transport from my VM to BigQuery. This is a 1.25x speed-up over using GZIP-compressed CSVs for transport.
The 16 GB of Parquet is 4 GB larger than the GZIP-compressed CSV files but the disk space and bandwidth savings failed to have a positive impact on the end-to-end transfer time. To add to this, ClickHouse took better advantage of the cores available during the 14-thread dump to Parquet versus what pigz could do.
The Parquet files use Snappy compression. Snappy was designed to compress faster while accepting the trade-off of lower compression ratios compared to other codecs. Storage and network throughput rates have increased faster than single-core compute throughput has in the past 20 years. When a file will be consumed by millions of people, the compression ratio is key and it's worth taking longer to compress. But when a file is only ever consumed once, it's more important to get to the point where the file has finished decompressing on the consumer's side as quickly as possible.
ClickHouse's Snappy Compression
I'll dump a single Parquet file of the dataset and then pick it apart below.
$ clickhouse client \
--query='SELECT revision,
from_date,
to_date,
geom,
h3_7,
h3_8,
h3_9
FROM pg_ch_bq_microsoft_buildings
FORMAT Parquet' \
> out.pq
$ python
The 130,099,920 records have been broken up into 1,987-row groups.
from collections import Counter
from operator import itemgetter
from pprint import pprint
import pyarrow.parquet as pq
pf = pq.ParquetFile('out.pq')
print(pf.metadata)
<pyarrow._parquet.FileMetaData object at 0x7fe07f37ab80>
created_by: parquet-cpp version 1.5.1-SNAPSHOT
num_columns: 7
num_rows: 130099920
num_row_groups: 1987
format_version: 1.0
serialized_size: 3839172
Each row group has 65,505 rows or less.
print(Counter(pf.metadata.row_group(rg).num_rows
for rg in range(0, pf.metadata.num_row_groups)))
Counter({65505: 1986, 6990: 1})
Every column has been compressed using Snappy.
print(set(pf.metadata.row_group(rg).column(col).compression
for col in range(0, pf.metadata.num_columns)
for rg in range(0, pf.metadata.num_row_groups)))
{'SNAPPY'}
2.6:1 was the highest compression ratio achieved among any of the columns in any of the row groups. Below are the details of the column that achieved this ratio.
lowest_val, lowest_rg, lowest_col = None, None, None
for rg in range(0, pf.metadata.num_row_groups):
for col in range(0, pf.metadata.num_columns):
x = pf.metadata.row_group(rg).column(col)
ratio = x.total_compressed_size / x.total_uncompressed_size
if not lowest_val or lowest_val > ratio:
lowest_val = ratio
lowest_rg, lowest_col = rg, col
print(pf.metadata.row_group(lowest_rg).column(lowest_col))
<pyarrow._parquet.ColumnChunkMetaData object at 0x7fe063224810>
file_offset: 12888987187
file_path:
physical_type: BYTE_ARRAY
num_values: 65505
path_in_schema: h3_9
is_stats_set: True
statistics:
<pyarrow._parquet.Statistics object at 0x7fe063211d10>
has_min_max: True
min: b'890c732020fffff'
max: b'8944db2db5bffff'
null_count: 0
distinct_count: 0
num_values: 65505
physical_type: BYTE_ARRAY
logical_type: None
converted_type (legacy): NONE
compression: SNAPPY
encodings: ('PLAIN_DICTIONARY', 'PLAIN', 'RLE')
has_dictionary_page: True
dictionary_page_offset: 12888564836
data_page_offset: 12888855960
total_compressed_size: 422351
total_uncompressed_size: 1101585
But of the 7 columns across the 1,987-row groups, over 30% have a compression ratio of 1:0.9 or worse. It's questionable if it was worth compressing these fields in the first place.
ratios = []
for rg in range(0, pf.metadata.num_row_groups):
for col in range(0, pf.metadata.num_columns):
x = pf.metadata.row_group(rg).column(col)
ratio = x.total_compressed_size / x.total_uncompressed_size
ratios.append('%.1f' % ratio)
pprint(sorted(Counter(ratios).items(),
key=itemgetter(0)))
[('0.4', 2345),
('0.5', 4020),
('0.6', 1201),
('0.7', 841),
('0.8', 1236),
('0.9', 1376),
('1.0', 2890)]
In 2016, Snappy had its heuristics increased to be more aggressive at avoiding compressing data that is unlikely to yield strong results. But with ratios like 1:0.9, it would be interesting to see if this could be taken further by turning off compression on a per-column basis.
Google also has a drop-in S2 extension for Snappy but support has yet to find its way into BigQuery. When I reviewed a Go and Assembler implementation of S2 in 2021, I found it could speed up compression by 4.2x and decompression by 1.7x over regular Snappy. Klaus Post, the author of the S2 utility, noted the speed-up should have been even greater had it not been for the I/O limitations of the laptop I ran the benchmark on.
Klaus has since pointed me to a benchmarks sheet where he managed to reduce a ~6 GB JSON file by 83% at a rate of 15 GB/s on a 16-core, AMD Ryzen 3950X. LZ4 took 10x longer to achieve a similar compression ratio on the same workload and GZIP took 74x longer. Snappy only ever managed a 75% reduction but even that was at a rate 16.5x slower than S2's 83% reduction rate.
Can Rust Do It Faster?
BigQuery also supports LZO and ZSTD compression in Parquet files so there is potential for further optimisations. I found json2parquet which is a Rust-based utility that can convert JSONL into Parquet files. It doesn't support LZO at this time but Snappy and ZStandard are both supported.
Shapefiles can be converted into JSONL quickly with ogr2ogr so potentially ClickHouse could be removed from the pipeline if json2parquet is quick enough.
I produced a JSONL extract of the California dataset. It has 11M records and is 3 GB in uncompressed JSONL format.
$ ogr2ogr -f GeoJSONSeq /vsistdout/ California.geojson \
| jq -c '.properties * {geom: .geometry|tostring}' \
> California.jsonl
$ head -n1 California.jsonl | jq .
{
"release": 1,
"capture_dates_range": "",
"geom": "{\"type\":\"Polygon\",\"coordinates\":[[[-114.127454,34.265674],[-114.127476,34.265839],[-114.127588,34.265829],[-114.127565,34.265663],[-114.127454,34.265674]]]}"
}
I then converted that file into Parquet with ClickHouse. It took 32 seconds on my 2020 MacBook Pro. The resulting file is 793 MB in size.
$ cat California.jsonl \
| clickhouse local \
--input-format JSONEachRow \
-q "SELECT *
FROM table
FORMAT Parquet" \
> cali.snappy.pq
The then did the same with json2parquet. The following was compiled with rustc 1.66.0 (69f9c33d7 2022-12-12).
$ git clone https://github.com/domoritz/json2parquet/
$ cd json2parquet
$ RUSTFLAGS='-Ctarget-cpu=native' \
cargo build --release
The following took 43.8 seconds to convert the JSONL into PQ with a resulting file size of 815 MB.
$ target/release/json2parquet \
-c snappy \
California.jsonl \
California.snappy.pq
The only major difference I found was that json2parquet produced 12 row groups in its Parquet file and ClickHouse produced 306.
I did produce a ZStandard-compressed Parquet file as well with json2parquet and although the resulting file was 531 MB, it took 48 seconds to produce. Neither of these will reduce the compression overhead in ClickHouse.
I'd like to see if ClickHouse could produce a ZStandard-compressed Parquet file faster than its Snappy-compressed files but there aren't any CLI flags to switch the Parquet compression codec at this time.
Digging into the Rust Executable
I did check that the Rust binary is using vectorised instructions. The following was on an Ubuntu 20 machine.
$ RUSTFLAGS='--emit asm -Ctarget-cpu=native' \
cargo build --release
$ grep -P '\tv[a-ilmopr-uxz][a-il-vx]{2}[a-z0-9]{0,10}' \
target/release/deps/parquet-9a152318b60fbda6.s \
| head
vpxor %xmm0, %xmm0, %xmm0
vpcmpeqd %xmm0, %xmm0, %xmm0
vmovdqa %xmm0, (%rsp)
vpxor %xmm0, %xmm0, %xmm0
vpcmpeqd %xmm0, %xmm0, %xmm0
vmovdqa %xmm0, (%rsp)
vmovdqu 8(%rax), %xmm0
vmovdqu 8(%rax), %xmm1
vmovq %xmm0, %rsi
vmovdqa %xmm1, (%rsp)
I then ran 10 lines of JSON through both ClickHouse and json2parquet to see what strace reports.
$ sudo strace -wc \
target/release/json2parquet \
-c snappy \
../cali10.jsonl \
test.snappy.pq
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
61.30 0.007141 16 434 write
21.66 0.002523 280 9 openat
4.33 0.000504 19 26 mmap
2.73 0.000318 317 1 execve
2.09 0.000244 16 15 read
...
There were 434 calls to write made by json2parquet which is where it spent 61% of its time. ClickHouse only made 2 calls to write with the same workload.
$ sudo strace -wc \
clickhouse local \
--input-format JSONEachRow \
-q "SELECT *
FROM table
FORMAT Parquet" \
< ../cali10.jsonl \
> cali.snappy.pq
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
29.52 0.019018 1584 12 futex
21.15 0.013625 63 214 gettid
11.19 0.007209 514 14 mprotect
11.06 0.007123 791 9 4 stat
8.72 0.005617 108 52 close
5.16 0.003327 1109 3 poll
2.19 0.001412 23 60 mmap
2.09 0.001344 39 34 1 openat
1.27 0.000816 18 44 read
...
0.15 0.000098 48 2 write
I thought that there could be an excessive number of context switches or page faults slowing json2parquet down but both of these occurred an order of magnitude more with ClickHouse.
$ sudo apt-get install \
linux-tools-common \
linux-tools-generic \
linux-tools-`uname -r`
$ sudo perf stat -dd \
target/release/json2parquet \
-c snappy \
../cali10.jsonl \
test.snappy.pq
1 context-switches # 201.206 /sec
198 page-faults # 39.839 K/sec
$ sudo perf stat -dd \
clickhouse local \
--input-format JSONEachRow \
-q "SELECT *
FROM table
FORMAT Parquet" \
< ../cali10.jsonl \
> cali.snappy.pq
44 context-switches # 372.955 /sec
4997 page-faults # 42.356 K/sec
Dominik Moritz, a researcher at Apple and one of the co-authors of Altair is the developer behind json2parquet. I raised a ticket asking him if there are any compilation settings I could adjust.
But given his project is made up of 193 lines of Rust and is largely dependent on the Rust implementation of Apache Arrow, I suspect that the performance bottleneck is either in Apache Arrow or that more compression settings need to be exposed if there are any performance improvements to be found.
A day after I originally looked into this I ran the benchmark on a fresh 16-core VM while collecting telemetry for the Apache Arrow team. The performance difference ended up being 4x between json2parquet and ClickHouse. During the re-run, I spotted json2parquet maxing out a single core while ClickHouse was better able to take advantage of multiple cores.
How's Python's Performance?
I found using PyArrow was 1.38x slower than ClickHouse, Awkward Array was 1.5x slower and fastparquet was 3.3x slower.
After raising the above performance tickets I decided to be fair to the ClickHouse project and see if there were any obvious performance improvements I could make with their offering as well.
Fixing GIS Data Delivery
It would be great to see data vendors deliver data straight into the Cloud Databases of their customers. It would save a lot of client time that's spent converting and uploading files. The Switch from Shapefile campaign notes there are at least 80 vector-based GIS file formats in use and knowing the pros and cons of each of these formats for your use case is a lengthy learning exercise.
Much of the GIS world is focused on city and state-level problems so it's common to see Shapefiles partitioned to at least the state level. When your problems are across the whole of the USA or larger, you're often dealing with datasets that are at least 100M rows in size. 100M-row datasets in PostgreSQL can be really slow to work with.
It would also be good to see GEOS, GDAL and PROJ integrated into ClickHouse. This would give users much of the functionality of PostGIS in what is one of the most performant open source databases. 100M-row datasets are small by ClickHouse's standards but the lack of GIS functionality is holding it back.
Formats like GeoParquet should see strong adoption when they're the preferred file-based transport for USA-wide GIS datasets if there is strong compatibility with a GIS-enhanced ClickHouse. I've seen a 400 GB PostgreSQL table compress down into 16 GB of GeoParquet. Dragging files of that size onto QGIS on a laptop will render it unresponsive for some time but pointing QGIS at that sort of dataset in a GIS-enhanced ClickHouse would be a different matter altogether.