In this post, I'll walk you through building a heatmap using freely available CSV and geospatial data. This post will make use of Python, ClickHouse and QGIS, a toolchain that is both open source and free of charge. The result should look like the following.
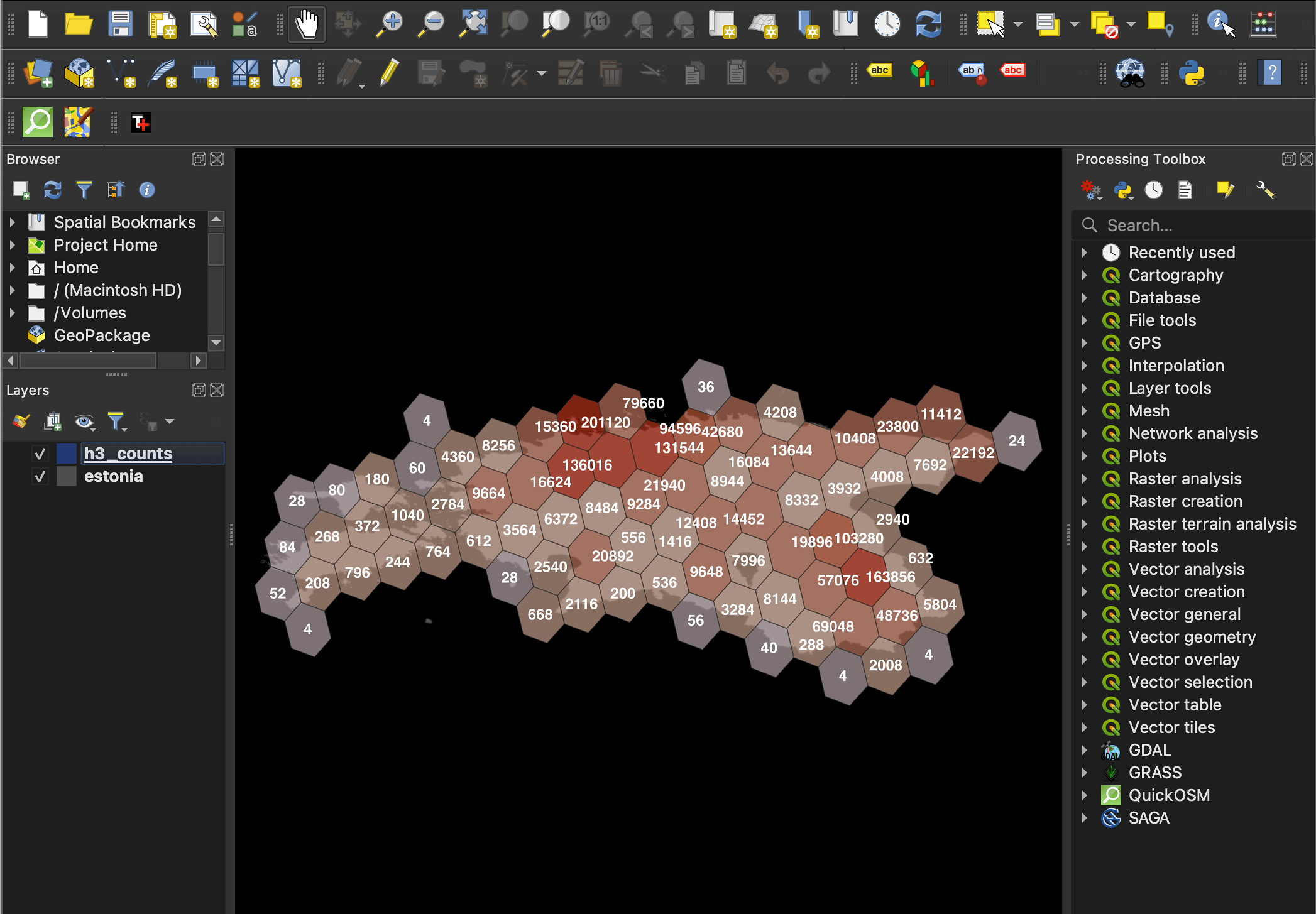
The above map depicts the number of cell phone tower observations made in Estonia by the OpenCelliD project. The observation points are grouped into hexagons allowing for hotspots to appear much clearer. The hexagon technology used is called H3 and was developed by Uber. I discuss it in detail in my Faster Geospatial Enrichment post.
Keep in mind that QGIS has a large and rich ecosystem of Python-based plugins. There is a chance that I've failed to find a plugin that would wrap up much of the instructions below into a shorter workflow.
Outside of Uber's C-based H3 library, this task could be entirely Python-based by swapping out ClickHouse for SQLite which is built into Python. I tend not to use SQLite for datasets above ten million rows for performance reasons but that doesn't mean it's incapable of the work ClickHouse is doing.
Installing Prerequisites
I'm using a fresh install of Ubuntu 20.04 LTS with an Intel Core i5 4670K clocked at 3.4 GHz, 16 GB of DDR3 RAM and 250 GB of NVMe SSD capacity.
Below I'll install Python and some build tools used throughout this post.
$ sudo apt update
$ sudo apt install \
build-essential \
jq \
libssl-dev \
python3-virtualenv
Uber's H3 library requires cmake v3.20+ but Ubuntu 20 only ships with v3.16. I'll build and install v3.20 below.
$ wget -c https://github.com/Kitware/CMake/releases/download/v3.20.0/cmake-3.20.0.tar.gz
$ tar -xzf cmake-3.20.0.tar.gz
$ cd cmake-3.20.0
$ ./bootstrap --parallel=$(nproc)
$ make -j$(nproc)
$ sudo make install
The following will compile and install Uber's H3 library.
$ git clone https://github.com/uber/h3 ~/uber_h3
$ mkdir -p ~/uber_h3/build
$ cd ~/uber_h3/build
$ cmake ..
$ make -j$(nproc)
$ sudo make install
As of this writing, the following installs ClickHouse version 22.7.1.1928.
$ cd ~
$ curl https://clickhouse.com/ | sh
$ sudo ./clickhouse install
$ sudo clickhouse start
I'll set up a Python virtual environment and install a few packages.
$ virtualenv ~/.towers
$ source ~/.towers/bin/activate
$ python3 -m pip install \
csvkit \
geojson \
h3
Part of this walk-through will use QGIS which is a desktop application. It's cross-platform and should run on macOS, Ubuntu Desktop and Windows without issue. Version 3.26 is the one used in this post.
Extracting Cell Tower Data
OpenCelliD is a community project that collects GPS positions and network coverage patterns from cell towers around the globe. They produce a 45M-record dataset that is refreshed daily. This dataset is delivered as a GZIP-compressed CSV file. Below I'll download and import the dataset into ClickHouse. Please replace the token in the URL with your own if you want to try this as well.
$ cd ~
$ wget "https://opencellid.org/ocid/downloads?token=...&type=full&file=cell_towers.csv.gz"
This is what the first few records look like.
$ gunzip -c cell_towers.csv.gz \
| head -n5 \
| csvlook -I
| radio | mcc | net | area | cell | unit | lon | lat | range | samples | changeable | created | updated | averageSignal |
| ----- | --- | --- | ---- | ------ | ---- | --------- | --------- | ----- | ------- | ---------- | ---------- | ---------- | ------------- |
| UMTS | 262 | 2 | 801 | 86355 | 0 | 13.285512 | 52.522202 | 1000 | 7 | 1 | 1282569574 | 1300155341 | 0 |
| GSM | 262 | 2 | 801 | 1795 | 0 | 13.276907 | 52.525714 | 5716 | 9 | 1 | 1282569574 | 1300155341 | 0 |
| GSM | 262 | 2 | 801 | 1794 | 0 | 13.285064 | 52.524 | 6280 | 13 | 1 | 1282569574 | 1300796207 | 0 |
| UMTS | 262 | 2 | 801 | 211250 | 0 | 13.285446 | 52.521744 | 1000 | 3 | 1 | 1282569574 | 1299466955 | 0 |
I'll create a table in ClickHouse which will be both compressed and columnar-optimised for this dataset.
$ clickhouse client
CREATE TABLE cell_towers (
radio Enum8('' = 0,
'CDMA' = 1,
'GSM' = 2,
'LTE' = 3,
'NR' = 4,
'UMTS' = 5),
mcc UInt16,
net UInt16,
area UInt16,
cell UInt64,
unit Int16,
lon Float64,
lat Float64,
range UInt32,
samples UInt32,
changeable UInt8,
created DateTime,
updated DateTime,
averageSignal UInt8
) ENGINE = MergeTree
ORDER BY (radio, mcc, net, created);
The following will decompress and import the CSV data into ClickHouse.
$ gunzip -c cell_towers.csv.gz \
| clickhouse client \
--query "INSERT INTO cell_towers
FORMAT CSVWithNames"
The above table is 1.2 GB in ClickHouse's internal MergeTree storage format. This is a 3.2x reduction from the original 3.88 GB of decompressed CSV data that was imported.
The mcc column refers to the Mobile Country Code which is operator and country-specific. I'll import another dataset that will link this identifier to the country to which each record refers.
UPDATE: As of February 2023, the files in the repository are blank. I've added a checkout command to revert to the last good version of the dataset.
$ git clone https://github.com/musalbas/mcc-mnc-table
$ cd mcc-mnc-table
$ git checkout a45a032fa76d119c053344f176d25673d55767c1
$ cd ..
This is an example of a few of the records in this dataset.
$ (head -n1 mcc-mnc-table/mcc-mnc-table.csv;
grep -i elisa mcc-mnc-table/mcc-mnc-table.csv) \
| csvlook -I
| MCC | MCC (int) | MNC | MNC (int) | ISO | Country | Country Code | Network |
| --- | --------- | --- | --------- | --- | ------- | ------------ | ------- |
| 248 | 584 | 02 | 47 | ee | Estonia | 372 | Elisa |
| 244 | 580 | 05 | 95 | fi | Finland | 358 | Elisa |
| 244 | 580 | 21 | 543 | fi | Finland | 358 | Elisa |
| 244 | 580 | 06 | 111 | fi | Finland | 358 | Elisa |
| 244 | 580 | 05 | 95 | fi | Finland | 358 | Elisa |
I'll create a table in ClickHouse for this dataset.
$ clickhouse client
CREATE TABLE mcc (
mcc UInt16,
iso VARCHAR(2),
country_name VARCHAR(255),
network_name VARCHAR(255)
) ENGINE = MergeTree
ORDER BY (mcc);
I only want 4 of the 8 fields as I'm only interested in the country being operated in. The operators listed are broken down by network which I'm not interested in. I'll cut out the 4 fields of interest and make sure the records are unique to avoid duplicates from the network breakdown.
$ csvcut -c 1,5,6,8 mcc-mnc-table/mcc-mnc-table.csv \
| uniq \
| clickhouse client \
--input_format_with_names_use_header=0 \
--query "INSERT INTO mcc FORMAT CSVWithNames"
I'll now create a table counting the number of observations in each hexagon at zoom level 4 by radio technology and country across the entire 45M record dataset.
$ clickhouse client
CREATE TABLE h3_sample_cnt ENGINE = Log() AS
SELECT a.radio,
b.iso,
b.country_name,
geoToH3(a.lon, a.lat, 4) AS h3_4,
sum(samples) AS samples_cnt
FROM cell_towers a
LEFT JOIN mcc b ON a.mcc = b.mcc
GROUP BY radio,
iso,
country_name,
h3_4;
The above aggregated 45,841,845 rows into 91,223 results. The Mobile Country Code list has 1,865 distinct country-provider pairs but only 225 of those are mentioned in the cell_towers dataset.
The following will extract 78 records that are specific to Estonia's 3G observations in CSV format.
$ clickhouse client \
--query "SELECT HEX(h3_4) h3,
samples_cnt
FROM h3_sample_cnt
WHERE iso = 'ee'
AND radio = 'UMTS'
FORMAT CSV" \
> h3_samples_ee.csv
Building GeoJSON
Below Uber's H3 Python library will be fed index codes of each hexagon and will output a polygon of the area each cover. This will then be paired with the observation count for the said hexagon. I'll be using the geojson Python library to help construct a valid GeoJSON file with the data produced.
$ python3
import csv
from geojson import (dumps,
Feature,
FeatureCollection,
Polygon)
import h3
fc = FeatureCollection([
Feature(geometry=Polygon([h3.h3_to_geo_boundary(h3_id,
geo_json=True)]),
properties={'sample_cnt': sample_cnt})
for h3_id, sample_cnt in csv.reader(open('h3_samples_ee.csv'))])
open('h3_counts.geojson', 'w').write(dumps(fc))
This is what the first 40 lines of the GeoJSON file look like.
$ cat h3_counts.geojson | jq | head -n40
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"geometry": {
"type": "Polygon",
"coordinates": [
[
[
57.642913,
26.023269
],
[
57.723616,
25.808102
],
[
57.977862,
25.748115
],
[
58.152881,
25.903081
],
[
58.073275,
26.118996
],
[
57.817547,
26.179198
]
]
]
},
"properties": {
"sample_cnt": 3284
}
Styling In QGIS
I'll first set up a basemap for Estonia in QGIS. It is possible to use extracts of continents, countries and states from OpenStreetMap by simply dragging OSM files into QGIS. But with that said, the larger the file, the longer it'll take QGIS to render so I've opted to use a small GeoJSON outline of Estonia's mainland and larger islands instead.
$ git clone https://github.com/buildig/EHAK
Drag geojson/estonia.json into a new QGIS document. Then drag h3_counts.geojson on top of that. You should see two layers listed in the bottom left of the UI. The hexagons at this point aren't partially transparent so they'll obstruct the basemap.
Left click the h3_counts layer, click the "Symbology" tab on the left and click "Simple Fill" at the top. Next to the "fill color" field in the middle of the dialog, click the equation icon and then "Edit" from the drop-down menu. Paste the following into the expression text box to the left.
CASE
WHEN "sample_cnt" >= 120000 THEN '#e93a27'
WHEN "sample_cnt" >= 80000 THEN '#ef684b'
WHEN "sample_cnt" >= 9000 THEN '#ed8d75'
WHEN "sample_cnt" >= 100 THEN '#f7c4b1'
ELSE '#e5cccf'
END
Then click "OK".
Above "Simple Fill" at the top click "Fill". A slider will appear in the centre of the dialog setting the opacity amount. Adjust this to your tastes. This will allow Estonia's geographic outline to appear underneath the hexagons on the map.
Then click "Apply" and "OK".