In May, Nature published an article detailing Oak Ridge National Laboratory's (ORNL) new, AI-generated US Building Dataset.
ORNL developed a convolutional neural network (CNN) that extracted vector-building footprints from Maxar's WorldView-02, WorldView-03, QuickBird, GeoEye-1 satellite imagery as well as the National Agriculture Imagery Program's (NAIP).
Google and Microsoft have both already published building datasets that were produced from satellite imagery but ORNL's focused on adding much more metadata around the address and use of each building. Lightbox, OpenStreetMap (OSM) and several US government agencies supplied data to help enrich this dataset.
Compared to anything I've seen from Microsoft and Google, this dataset appears to have much more accurate building footprints to the point I initially thought they were manually surveyed.
In this post, I'll walk through downloading and analysing ORNL's 131M US Building Dataset.
The ETL scripts for this post will be available on GitHub and under an MIT License.
My Workstation
I'm using a 6 GHz Intel Core i9-14900K CPU. It has 8 performance cores and 16 efficiency cores with a total of 32 threads and 32 MB of L2 cache. It has a liquid cooler attached and is housed in a spacious, full-sized, Cooler Master HAF 700 computer case. I've come across videos on YouTube where people have managed to overclock the i9-14900KF to 9.1 GHz.
The system has 96 GB of DDR5 RAM clocked at 6,000 MT/s and a 5th-generation, Crucial T700 4 TB NVMe M.2 SSD which can read at speeds up to 12,400 MB/s. There is a heatsink on the SSD to help keep its temperature down. This is my system's C drive.
The system is powered by a 1,200-watt, fully modular, Corsair Power Supply and is sat on an ASRock Z790 Pro RS Motherboard.
I'm running Ubuntu 22 LTS via Microsoft's Ubuntu for Windows on Windows 11 Pro. In case you're wondering why I don't run a Linux-based desktop as my primary work environment, I'm still using an Nvidia GTX 1080 GPU which has better driver support on Windows and I use ArcGIS Pro from time to time which only supports Windows natively.
Installing Prerequisites
I'll use Python and a few other tools to help analyse the data in this post.
$ sudo apt update
$ sudo apt install \
jq \
python3-pip \
python3-virtualenv
I'll set up a Python Virtual Environment and install some dependencies.
$ virtualenv ~/.ornl
$ source ~/.ornl/bin/activate
$ pip install \
xmljson
I've been working on a Parquet debugging tool. I'll use it to examine the results of Parquet compression in this post.
$ git clone https://github.com/marklit/pqview \
~/pqview
$ python3 -m pip install \
-r ~/pqview/requirements.txt
I'll use DuckDB, along with its H3, JSON, Lindel, Parquet and Spatial extensions, in this post.
$ cd ~
$ wget -c https://github.com/duckdb/duckdb/releases/download/v1.1.1/duckdb_cli-linux-amd64.zip
$ unzip -j duckdb_cli-linux-amd64.zip
$ chmod +x duckdb
$ ~/duckdb
INSTALL h3 FROM community;
INSTALL lindel FROM community;
INSTALL json;
INSTALL parquet;
INSTALL spatial;
I'll set up DuckDB to load every installed extension each time it launches.
$ vi ~/.duckdbrc
.timer on
.width 180
LOAD h3;
LOAD lindel;
LOAD json;
LOAD parquet;
LOAD spatial;
The maps in this post were rendered with QGIS version 3.38.0. QGIS is a desktop application that runs on Windows, macOS and Linux. The application has grown in popularity in recent years and has ~15M application launches from users all around the world each month.
I used QGIS' Tile+ plugin to add geospatial context with NASA's Blue Marble and Esri's World Imagery Basemaps to the maps. Esri's imagery has been tinted red and darkened to help contrast against overlapping vector data.
Downloading ORNL's Buildings Dataset
The following will download 56 ZIP files with a footprint of 42 GB.
$ mkdir -p ~/ornl_buildings
$ cd ~/ornl_buildings
$ curl -s https://disasters.geoplatform.gov/USA_Structures/ \
| grep -o 'https.*zip' \
> urls.txt
$ cat urls.txt | xargs -P4 -I% wget -c %
Geodatabase Format
The ZIP files contain Geodatabases for US States and territories. The largest gdbtable file within any one ZIP will contain the geometry and related metadata for that ZIP file's buildings.
$ unzip Deliverable20230630DE.zip
$ find Deliverable20230630DE/DE_Structures.gdb/*.gdbtable
The last file is the one with the data.
Deliverable20230630DE/DE_Structures.gdb/a00000001.gdbtable
Deliverable20230630DE/DE_Structures.gdb/a00000002.gdbtable
Deliverable20230630DE/DE_Structures.gdb/a00000003.gdbtable
Deliverable20230630DE/DE_Structures.gdb/a00000004.gdbtable
Deliverable20230630DE/DE_Structures.gdb/a00000005.gdbtable
Deliverable20230630DE/DE_Structures.gdb/a00000006.gdbtable
Deliverable20230630DE/DE_Structures.gdb/a00000007.gdbtable
Deliverable20230630DE/DE_Structures.gdb/a0000000b.gdbtable
Below is an example record.
$ ~/duckdb \
-json \
-c "FROM ST_READ('Deliverable20230630DE/DE_Structures.gdb/a0000000b.gdbtable')
LIMIT 1" \
| jq -S .
[
{
"BUILD_ID": 1,
"CENSUSCODE": "10005051205",
"FIPS": "10005",
"HEIGHT": null,
"H_ADJ_ELEV": null,
"IMAGE_DATE": "2018-03-24 00:00:00",
"IMAGE_NAME": "104001003A728B00",
"LATITUDE": 38.45130373941299,
"LONGITUDE": -75.05453241762243,
"L_ADJ_ELEV": null,
"OCC_CLS": "Unclassified",
"OUTBLDG": null,
"PRIM_OCC": "Unclassified",
"PROD_DATE": "2020-05-19 00:00:00",
"PROP_ADDR": "39047 GRAYS LANE",
"PROP_CITY": "FENWICK ISLAND",
"PROP_ST": "Delaware",
"PROP_ZIP": "19944",
"REMARKS": null,
"SEC_OCC": null,
"SOURCE": "ORNL",
"SQFEET": 638.9439,
"SQMETERS": 59.35989,
"Shape": "MULTIPOLYGON (((-75.05458907399998 38.45132615500006, -75.05446143999995 38.45132590600008, -75.05446157999995 38.451281298000026, -75.05458921299999 38.451281546000075, -75.05458907399998 38.45132615500006)))",
"Shape_Area": 5.693573654220543e-09,
"Shape_Length": 0.00034448492017148994,
"USNG": "18S VH 95241 55891",
"UUID": "{9d9aaaa2-f19a-4881-a4cc-daafad3b98d1}",
"VAL_METHOD": "Automated"
}
]
I'll convert Delaware's Geodatabase into a spatially-sorted, ZStandard-compressed, Parquet file.
$ ~/duckdb
COPY(
SELECT * EXCLUDE(Shape),
ST_ASWKB(Shape) AS geom
FROM ST_READ('Deliverable20230630DE/DE_Structures.gdb/a0000000b.gdbtable')
ORDER BY HILBERT_ENCODE([ST_Y(ST_CENTROID(Shape)),
ST_X(ST_CENTROID(Shape))]::double[2])
) TO 'DE.pq' (
FORMAT 'PARQUET',
CODEC 'ZSTD',
COMPRESSION_LEVEL 22,
ROW_GROUP_SIZE 15000);
The above 106 MB ZIP file contains 219 MB of uncompressed Geodatabase data. After being converted into Parquet, it now has a footprint of 42 MB. Below is the space usage breakdown by column.
$ python3 ~/pqview/main.py \
sizes \
DE.pq
20.9 MB geom
7.3 MB UUID
2.9 MB Shape_Length
2.7 MB Shape_Area
2.0 MB LATITUDE
2.0 MB LONGITUDE
1.3 MB SQFEET
1.3 MB SQMETERS
1.2 MB PROP_ADDR
1.2 MB USNG
604.8 kB BUILD_ID
181.1 kB HEIGHT
50.2 kB PRIM_OCC
31.8 kB OCC_CLS
20.3 kB PROP_CITY
19.4 kB PROP_ZIP
16.9 kB CENSUSCODE
16.1 kB IMAGE_DATE
15.0 kB PROD_DATE
14.8 kB IMAGE_NAME
9.9 kB VAL_METHOD
9.7 kB SOURCE
2.0 kB FIPS
1.8 kB PROP_ST
1.2 kB REMARKS
862 Bytes SEC_OCC
862 Bytes OUTBLDG
862 Bytes H_ADJ_ELEV
862 Bytes L_ADJ_ELEV
Repackaging as Parquet
I'll convert the entire dataset's ~95 GB of uncompressed Geodatabase files into 15 GB worth of Parquet files.
$ for FILENAME in `ls Deliverable*.zip`; do
STATE=`echo $FILENAME | grep -oE '[A-Z]{2}\.zip' | sed 's/.zip//g'`
if ! test -f "$STATE.pq"; then
echo $STATE
mkdir -p working
rm working/* || true
unzip -qnj $FILENAME -d working
GDB=`ls -S working/*.gdbtable | head -n1`
echo "COPY(
SELECT * EXCLUDE(Shape),
Shape geom
FROM ST_READ('$GDB', keep_wkb=TRUE)
WHERE ('0x' || substr(Shape::BLOB::TEXT, 7, 2))::int < 8
AND ST_Y(ST_CENTROID(Shape::GEOMETRY)) IS NOT NULL
AND ST_X(ST_CENTROID(Shape::GEOMETRY)) IS NOT NULL
ORDER BY HILBERT_ENCODE([
ST_Y(ST_CENTROID(Shape::GEOMETRY)),
ST_X(ST_CENTROID(Shape::GEOMETRY))]::double[2])
) TO '$STATE.pq' (
FORMAT 'PARQUET',
CODEC 'ZSTD',
COMPRESSION_LEVEL 22,
ROW_GROUP_SIZE 15000);" \
| ~/duckdb
fi
done
The above did need to exclude some records based on their type of geometry as the GEOS library DuckDB's spatial extension uses only supports seven types of geometry.
Some records contain geometry that DuckDB is unable to calculate a centroid for so I needed the exclude them as well.
Apple-specific metadata files were included in some ZIP files. unzip has a flag to not overwrite these files as the folder structure is discarded during the ZIP's decompression.
DuckDB can embed key-value metadata into Parquet files via a KV_METADATA option. It might be worth exploring packaging the metadata described below into each Parquet file so that they are more self-contained.
Processing Metadata
Each ZIP file contains a large amount of metadata about how the resulting dataset was produced. The metadata for Delaware is 23 KB when uncompressed and converted into JSON.
$ unzip -p Deliverable20230630DE.zip \
Deliverable20230630DE/DE_Structures_metadata.xml \
| xml2json \
| jq -S . \
> metadata.json # 23 KB
Each enrichment step is documented in detail.
$ jq -S .dataqual.lineage.procstep metadata.json
[
{
"procdate": 20200430,
"procdesc": "Scalable High-Resolution Imagery-Based Building Extraction Pipeline (SCRIBE): High-resolution multispectral imagery is obtained for the area of interest. The raw imagery (Level-1B product) is then pan-sharpened and orthorectified. Complete coverage with minimal cloud cover includes overhead imagery and LiDAR-derived footprints with a spatial resolution less than 0.7 meters. Once imagery pre-processing completes, high performance computing (HPC) environments at ORNL are used to apply a convolutional neural network (CNN) model to the imagery to automatically extract structure boundaries. "
},
{
"procdate": 20200506,
"procdesc": "Verification and Validation Model (VVM): Verification and validation of the output produced from SCRIBE is conducted by a machine learning model to remove potential false positives. "
},
{
"procdate": 20200506,
"procdesc": "Regularization: The visual representation of the structures has been improved to represent structure geometry more accurately as compared to the imagery-derived raster representations from the SCRIBE pipeline. This step also reduces the number of vertices represented by a structure, thus reducing file size and improving render speeds."
},
{
"procdate": 20211229,
"procdesc": "Attribution and Metadata: Population of some attributes is incomplete and identified in the Entity and Attribute Information section of this metadata."
},
{
"procdate": 20230630,
"procdesc": "Phase 2 attribute expansion: Population of OCC_CLS, PRIM_OCC, PROP_ADDR, PROP_CITY, PROP_ZIP, and PROP_ST with best available data. Coverage of address related fields maybe incomplete."
}
]
The imagery sources are listed.
$ jq -S '.dataqual.lineage.srcinfo[].srccitea' metadata.json
"133 Cities"
"NAIP"
"WV03"
"WV02"
"LBPD"
"HIFLD"
"Census HU"
"Census tracts"
"NAD"
How each source was used is also described.
$ jq -S '.dataqual.lineage.srcinfo[3]' metadata.json
{
"srccite": {
"citeinfo": {
"origin": "Maxar",
"pubdate": 20091108,
"title": "WorldView-2"
}
},
"srccitea": "WV02",
"srccontr": "Input Imagery from which features were extracted",
"srctime": {
"srccurr": "Observed",
"timeinfo": {
"rngdates": {
"begdate": 20160906,
"enddate": 20191028
}
}
},
"typesrc": "remote-sensing image"
}
The fields impacted by each source are also described.
$ jq -S '.eainfo.detailed.attr[:3]' metadata.json
[
{
"attrdef": "Internal feature number.",
"attrdefs": "Esri",
"attrdomv": {
"udom": "Sequential unique whole numbers that are automatically generated."
},
"attrlabl": "OBJECTID"
},
{
"attrdef": "Feature geometry.",
"attrdefs": "Esri",
"attrdomv": {
"udom": "Coordinates defining the features."
},
"attrlabl": "Shape"
},
{
"attrdef": "Unique ID for each feature.",
"attrdefs": "Oak Ridge National Laboratory",
"attrlabl": "BUILD_ID"
}
]
Finally, the spatial settings of the dataset.
$ jq -S '.spref' metadata.json
{
"horizsys": {
"geodetic": {
"denflat": 298.257223563,
"ellips": "WGS 1984",
"horizdn": "D WGS 1984",
"semiaxis": 6378137
},
"geograph": {
"geogunit": "Decimal Degrees",
"latres": 8.983152841195215e-09,
"longres": 8.983152841195215e-09
}
}
}
Unique Buildings
Each building's UUID is unique to that physical building. If a building is demolished and a new one is created, there will be two UUIDs on that parcel of land. At the moment, there are 131.8M UUIDs in this dataset.
$ ~/duckdb
SELECT COUNT(DISTINCT UUID) FROM READ_PARQUET('*.pq');
131811952
The H3 extension for DuckDB can throw errors if erroneous latitude and longitude values are fed to it. I've noticed both latitude and longitude fall outside of their valid ranges in this dataset.
.mode line
SELECT MIN(LATITUDE),
MAX(LATITUDE),
MIN(LONGITUDE),
MAX(LONGITUDE)
FROM READ_PARQUET('*.pq');
min(LATITUDE) = -14.363104424403035
max(LATITUDE) = 4332647.099997337
min(LONGITUDE) = -47766.96837265695
max(LONGITUDE) = 718848.8890845429
Around 32M buildings have height information in this dataset. Below I've calculated the maximum height for each zoom-level-3 hexagon.
I've added predicates to only use valid latitude and longitude values and avoid anything near the international dateline as the polygons for that area will cover the earth horizontally when rendered in QGIS.
COPY (
SELECT H3_CELL_TO_BOUNDARY_WKT(
H3_LATLNG_TO_CELL(LATITUDE,
LONGITUDE,
3))::geometry geom,
MAX(HEIGHT) as max_height
FROM READ_PARQUET('*.pq')
WHERE LONGITUDE < 170
AND LONGITUDE > -170
AND HEIGHT IS NOT NULL
GROUP BY 1
) TO 'max_height.h3_3.gpkg'
WITH (FORMAT GDAL,
DRIVER 'GPKG',
LAYER_CREATION_OPTIONS 'WRITE_BBOX=YES');
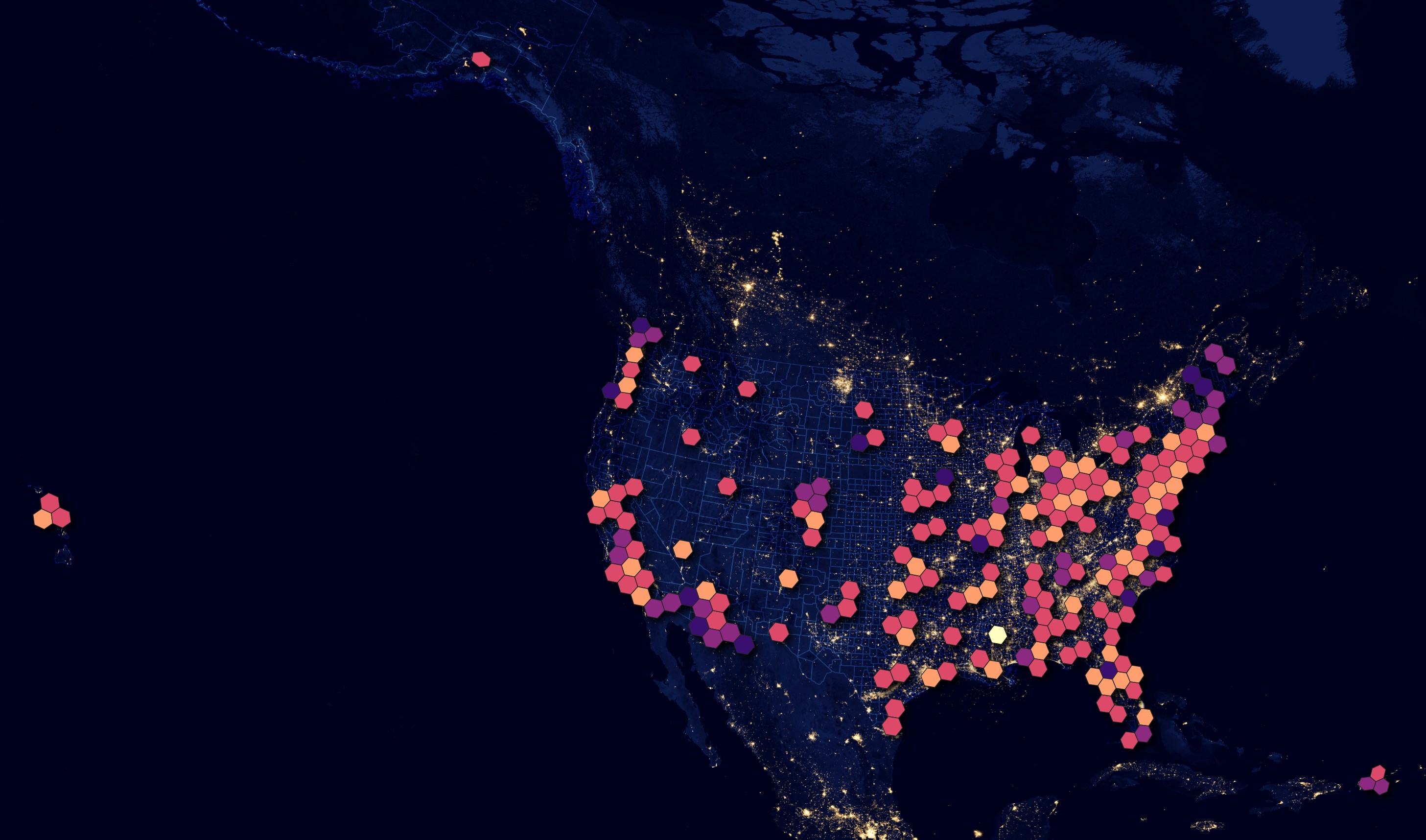
Building Uses
All but ~6M buildings in this dataset have an occupational class.
SELECT OCC_CLS,
COUNT(*)
FROM READ_PARQUET('*.pq')
GROUP BY 1
ORDER BY 2 DESC;
┌──────────────────┬──────────────┐
│ OCC_CLS │ count_star() │
│ varchar │ int64 │
├──────────────────┼──────────────┤
│ Residential │ 112422033 │
│ Unclassified │ 5928631 │
│ Commercial │ 5631343 │
│ Agriculture │ 3913083 │
│ Industrial │ 1324540 │
│ Government │ 958829 │
│ Education │ 810984 │
│ Assembly │ 573600 │
│ Utility and Misc │ 248909 │
└──────────────────┴──────────────┘
Here is an image of the occupational classes around Los Angeles International Airport (LAX).

There is also a primary occupancy field that describes the use of any building in greater detail.
SELECT PRIM_OCC,
COUNT(*)
FROM READ_PARQUET('*.pq')
GROUP BY 1
ORDER BY 2 DESC;
┌─────────────────────────────────┬──────────────┐
│ PRIM_OCC │ count_star() │
│ varchar │ int64 │
├─────────────────────────────────┼──────────────┤
│ Single Family Dwelling │ 96877836 │
│ Unclassified │ 7941798 │
│ Multi - Family Dwelling │ 6689708 │
│ Manufactured Home │ 6317390 │
│ Agriculture │ 3913083 │
│ Retail Trade │ 3063377 │
│ Light │ 1152866 │
│ Professional/Technical Services │ 1068094 │
│ General Services │ 695365 │
│ Entertainment and Recreation │ 622523 │
│ Pre-K - 12 Schools │ 490540 │
│ Personal and Repair Services │ 407753 │
│ Religious │ 389324 │
│ Temporary Lodging │ 363633 │
│ Wholesale Trade │ 269162 │
│ Non-Civilian Structures │ 189401 │
│ Aviation │ 189073 │
│ Colleges/Universities │ 179209 │
│ Community Center │ 175178 │
│ Other Educational Buildings │ 141235 │
│ Nursing Home │ 96576 │
│ Medical Office/Clinic │ 94729 │
│ Emergency Response │ 74063 │
│ Institutional Dormitory │ 63723 │
│ Metals/Minerals Processing │ 56371 │
│ Parking │ 55821 │
│ Food/Drugs/Chemicals │ 54896 │
│ Heavy │ 46620 │
│ Ground │ 38615 │
│ Hospital │ 24326 │
│ Theaters │ 12968 │
│ Veterinary/Pet │ 12144 │
│ Marine │ 10415 │
│ High Technology │ 8558 │
│ Indoor Arena │ 8149 │
│ Rail │ 7210 │
│ Construction │ 5229 │
│ Energy Control Monitoring │ 3596 │
│ Stadium │ 934 │
│ Banks │ 446 │
│ Convention Center │ 15 │
├─────────────────────────────────┴──────────────┤
│ 41 rows 2 columns │
└────────────────────────────────────────────────┘
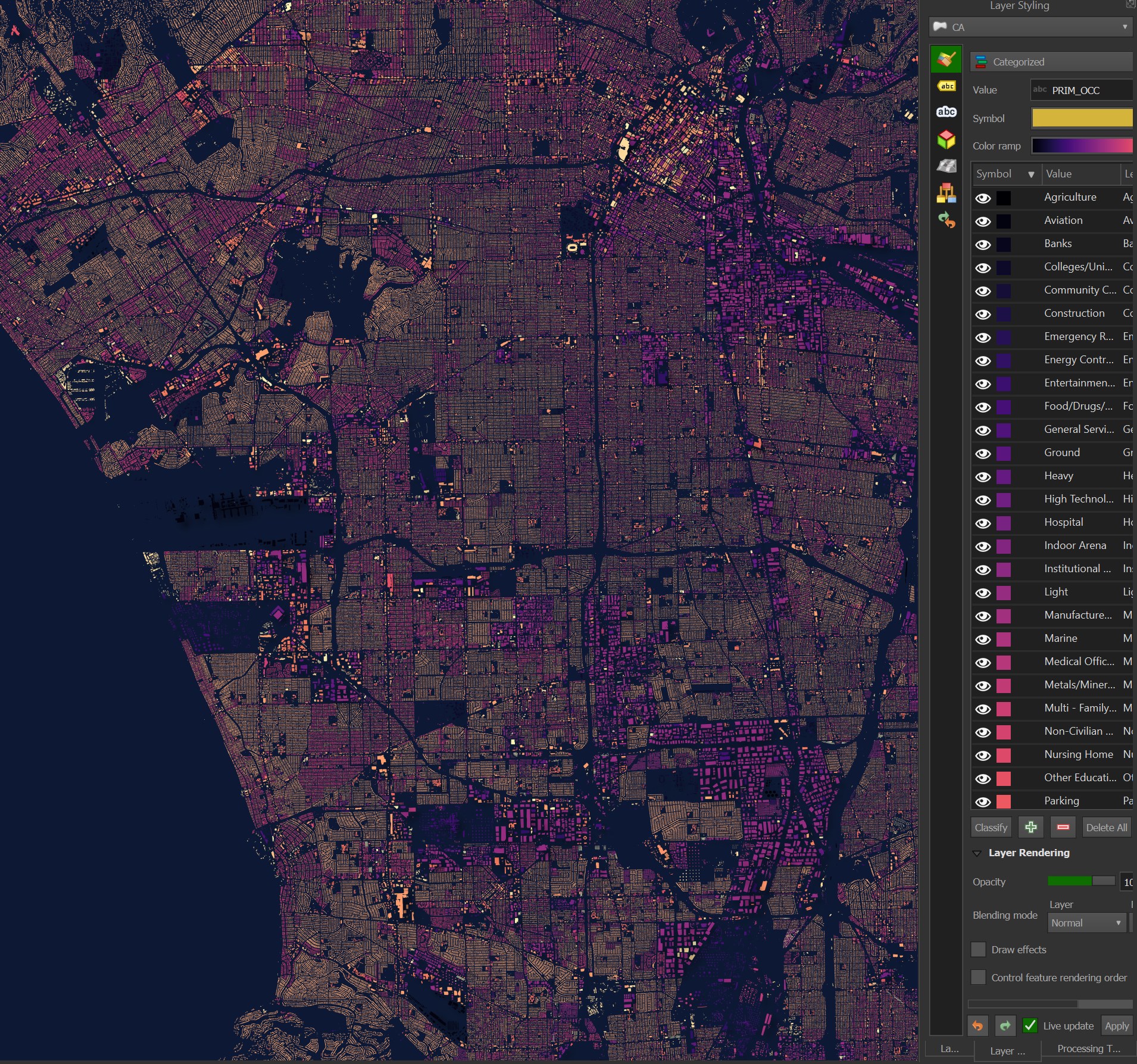
Building Addresses
Every record has a state name associated with it.
SELECT PROP_ST,
COUNT(*)
FROM READ_PARQUET('*.pq')
GROUP BY 1
ORDER BY 2 DESC
LIMIT 10;
┌────────────────┬──────────────┐
│ PROP_ST │ count_star() │
│ varchar │ int64 │
├────────────────┼──────────────┤
│ Texas │ 11597841 │
│ California │ 10931401 │
│ Florida │ 6987662 │
│ Ohio │ 5773395 │
│ New York │ 5015975 │
│ Pennsylvania │ 4987403 │
│ Illinois │ 4931783 │
│ Michigan │ 4925410 │
│ North Carolina │ 4790212 │
│ Georgia │ 3939753 │
├────────────────┴──────────────┤
│ 10 rows 2 columns │
└───────────────────────────────┘
But 69.5M records don't have a city name associated with them.
SELECT PROP_CITY,
COUNT(*)
FROM READ_PARQUET('*.pq')
GROUP BY 1
ORDER BY 2 DESC
LIMIT 10;
┌──────────────┬──────────────┐
│ PROP_CITY │ count_star() │
│ varchar │ int64 │
├──────────────┼──────────────┤
│ │ 69569842 │
│ HOUSTON │ 775873 │
│ CHICAGO │ 548972 │
│ SAN ANTONIO │ 544670 │
│ PHOENIX │ 478703 │
│ DALLAS │ 394747 │
│ JACKSONVILLE │ 369970 │
│ TUCSON │ 324066 │
│ FORT WORTH │ 304702 │
│ AUSTIN │ 303199 │
├──────────────┴──────────────┤
│ 10 rows 2 columns │
└─────────────────────────────┘
Almost 62M buildings don't have an address.
SELECT PROP_ADDR,
COUNT(*)
FROM READ_PARQUET('*.pq')
GROUP BY 1
ORDER BY 2 DESC
LIMIT 10;
┌─────────────────────────────┬──────────────┐
│ PROP_ADDR │ count_star() │
│ varchar │ int64 │
├─────────────────────────────┼──────────────┤
│ │ 61951398 │
│ 7329 SECO BLVD │ 105019 │
│ 5535 NORTHMOOR DR │ 73691 │
│ 15235 S TAMIAMI TRL │ 1304 │
│ 17200 WEST BELL ROAD │ 1197 │
│ 12850 SW 14 ST │ 1156 │
│ 3000 TANGLEWOOD PKWY OFFICE │ 1076 │
│ 14205 E COLONIAL DR │ 1074 │
│ 106 EVERGREEN LN │ 1062 │
│ 950 RIDGEWOOD AVE │ 1051 │
├─────────────────────────────┴──────────────┤
│ 10 rows 2 columns │
└────────────────────────────────────────────┘
Almost 68M are missing a ZIP code.
SELECT PROP_ZIP,
COUNT(*)
FROM READ_PARQUET('*.pq')
GROUP BY 1
ORDER BY 2 DESC
LIMIT 10;
┌──────────┬──────────────┐
│ PROP_ZIP │ count_star() │
│ varchar │ int64 │
├──────────┼──────────────┤
│ │ 67902480 │
│ 34953 │ 54681 │
│ 77494 │ 36753 │
│ 77449 │ 32062 │
│ 78641 │ 31926 │
│ 59901 │ 31363 │
│ 60629 │ 30671 │
│ 77573 │ 30621 │
│ 34950 │ 30495 │
│ 28655 │ 30459 │
├──────────┴──────────────┤
│ 10 rows 2 columns │
└─────────────────────────┘
Every building has a FIPS code.
SELECT FIPS,
COUNT(*)
FROM READ_PARQUET('*.pq')
GROUP BY 1
ORDER BY 2 DESC
LIMIT 10;
┌─────────┬──────────────┐
│ FIPS │ count_star() │
│ varchar │ int64 │
├─────────┼──────────────┤
│ 06037 │ 2442352 │
│ 04013 │ 1477631 │
│ 17031 │ 1320536 │
│ 48201 │ 1320215 │
│ 06073 │ 821650 │
│ 06059 │ 750570 │
│ 26163 │ 747480 │
│ 06065 │ 731839 │
│ 48113 │ 709529 │
│ 48439 │ 666556 │
├─────────┴──────────────┤
│ 10 rows 2 columns │
└────────────────────────┘
Every building has a Census code.
SELECT CENSUSCODE,
COUNT(*)
FROM READ_PARQUET('*.pq')
GROUP BY 1
ORDER BY 2 DESC
LIMIT 10;
┌─────────────┬──────────────┐
│ CENSUSCODE │ count_star() │
│ varchar │ int64 │
├─────────────┼──────────────┤
│ 30027030100 │ 9709 │
│ 48157673202 │ 9504 │
│ 40085094200 │ 8382 │
│ 55075960200 │ 8053 │
│ 48201542902 │ 8044 │
│ 38061955200 │ 8010 │
│ 38055961001 │ 7845 │
│ 38025962200 │ 7837 │
│ 55075960700 │ 7830 │
│ 08123002501 │ 7729 │
├─────────────┴──────────────┤
│ 10 rows 2 columns │
└────────────────────────────┘
Production Details
Below are the primary sources for each building.
SELECT SOURCE,
COUNT(*)
FROM READ_PARQUET('*.pq')
GROUP BY 1
ORDER BY 2 DESC;
┌─────────┬──────────────┐
│ SOURCE │ count_star() │
│ varchar │ int64 │
├─────────┼──────────────┤
│ ORNL │ 99696527 │
│ NGA │ 32109289 │
│ NOAA │ 6136 │
└─────────┴──────────────┘
Underlying imagery filenames are documented in the IMAGE_NAME field.
SELECT IMAGE_NAME,
COUNT(*)
FROM READ_PARQUET('*.pq')
GROUP BY 1
ORDER BY 2 DESC;
┌─────────────────────────────────────┬──────────────┐
│ IMAGE_NAME │ count_star() │
│ varchar │ int64 │
├─────────────────────────────────────┼──────────────┤
│ Li234-Los Angeles │ 2508188 │
│ Li279-Dallas │ 1126980 │
│ Li135-Washington │ 1059116 │
│ Li250-New York City │ 1052991 │
│ Li213-Chicago │ 1041121 │
│ Li241-San Fransico- Oakland │ 913385 │
│ Li238-Philadelphia- Wilmington │ 897701 │
│ Li272-Miami │ 846854 │
│ Li257-Phoenix │ 781002 │
│ Li219-Minneapolis │ 738935 │
│ Li227-Denver │ 723380 │
│ Li275-Detroit │ 544929 │
│ Li185-Houston │ 520854 │
│ Li244-Tampa Bay │ 515032 │
│ Li243-St. Louis │ 512304 │
│ Li271-Las Vegas │ 510711 │
│ Li239-San Antonio │ 507526 │
│ 1040010050CF1C00 │ 473934 │
│ Li218-Atlanta │ 458947 │
│ Li195-akron- cleveland │ 441440 │
│ · │ · │
│ · │ · │
│ · │ · │
│ m_3708663_sw_16_1_20140705_20141201 │ 1 │
│ m_3608240_sw_17_1_20140506_20140728 │ 1 │
│ m_3608662_sw_16_1_20140711_20141113 │ 1 │
│ m_3508437_sw_16_1_20140503_20140710 │ 1 │
│ m_4711831_sw_11_1_20130628_20130820 │ 1 │
│ 1045006 │ 1 │
│ 1050410001C9BB00 │ 1 │
│ 103001003FBA5200 │ 1 │
│ 1040010001064900 │ 1 │
│ 103001006AAA3500 │ 1 │
│ 1040010017225600 │ 1 │
│ m_4606936_ne_19_1_20130721_20131029 │ 1 │
│ m_3908414_ne_16_1_20130924_20131031 │ 1 │
│ 1043752 │ 1 │
│ 1045406 │ 1 │
│ m_4008604_nw_16_1_20141025_20141201 │ 1 │
│ m_3708856_se_16_1_20140623_20141201 │ 1 │
│ m_4711419_se_11_1_20130821_20131022 │ 1 │
│ m_4209707_ne_14_1_20140926_20141113 │ 1 │
│ m_3508655_se_16_1_20141022_20141113 │ 1 │
├─────────────────────────────────────┴──────────────┤
│ 20394 rows (40 shown) 2 columns │
└────────────────────────────────────────────────────┘
Below are the relationships between the imagery source and production dates. I need to look into what they mean by production further.
WITH a AS (
SELECT STRFTIME(IMAGE_DATE, '%Y') imagery_from,
STRFTIME(PROD_DATE, '%Y') produced_at,
COUNT(*) num_rec
FROM READ_PARQUET('*.pq')
GROUP BY 1, 2
)
PIVOT a
ON imagery_from
USING SUM(num_rec)
GROUP BY produced_at
ORDER BY produced_at;
┌─────────────┬────────┬────────┬────────┬────────┬────────┬────────┬─────────┬─────────┬─────────┬─────────┬──────────┬─────────┬─────────┬─────────┬─────────┬─────────┬──────────┬──────────┬─────────┬─────────┐
│ produced_at │ 2000 │ 2003 │ 2004 │ 2005 │ 2006 │ 2007 │ 2008 │ 2009 │ 2010 │ 2011 │ 2012 │ 2013 │ 2014 │ 2015 │ 2016 │ 2017 │ 2018 │ 2019 │ 2020 │ 2021 │
│ varchar │ int128 │ int128 │ int128 │ int128 │ int128 │ int128 │ int128 │ int128 │ int128 │ int128 │ int128 │ int128 │ int128 │ int128 │ int128 │ int128 │ int128 │ int128 │ int128 │ int128 │
├─────────────┼────────┼────────┼────────┼────────┼────────┼────────┼─────────┼─────────┼─────────┼─────────┼──────────┼─────────┼─────────┼─────────┼─────────┼─────────┼──────────┼──────────┼─────────┼─────────┤
│ 2000 │ 13008 │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
│ 2003 │ │ 65135 │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
│ 2004 │ │ │ 81034 │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
│ 2005 │ │ │ │ 77331 │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
│ 2006 │ │ │ │ │ 428349 │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
│ 2007 │ │ │ │ │ │ 255545 │ │ │ │ │ │ │ │ │ │ │ │ │ │ │
│ 2008 │ │ │ │ │ │ │ 2551704 │ │ │ │ │ │ │ │ │ │ │ │ │ │
│ 2009 │ │ │ │ │ │ │ │ 1433778 │ │ │ │ │ │ │ │ │ │ │ │ │
│ 2010 │ │ │ │ │ │ │ │ │ 2817831 │ │ │ │ │ │ │ │ │ │ │ │
│ 2011 │ │ │ │ │ │ │ │ │ │ 4443349 │ │ │ │ │ │ │ │ │ │ │
│ 2012 │ │ │ │ │ │ │ │ │ │ │ 10193895 │ │ │ │ │ │ │ │ │ │
│ 2013 │ │ │ │ │ │ │ │ │ │ │ │ 2439121 │ │ │ │ │ │ │ │ │
│ 2014 │ │ │ │ │ │ │ │ │ │ │ │ │ 2353654 │ │ │ │ │ │ │ │
│ 2015 │ │ │ │ │ │ │ │ │ │ │ │ │ │ 2616900 │ │ │ │ │ │ │
│ 2018 │ │ │ │ │ │ │ │ │ 14451 │ 51544 │ 164587 │ 206082 │ 146136 │ 1477598 │ 2543621 │ 3458766 │ 124530 │ │ │ │
│ 2019 │ │ │ │ │ 93 │ │ │ 4 │ 3285 │ 31067 │ 6262 │ 39932 │ 996916 │ 3402831 │ 6259885 │ 9390253 │ 11508572 │ 613431 │ │ │
│ 2020 │ │ │ │ │ │ │ │ 911 │ 127773 │ 229247 │ 338299 │ 801825 │ 2386198 │ 5424376 │ 6355909 │ 6350048 │ 11148082 │ 11520284 │ 483376 │ │
│ 2021 │ │ │ │ │ 91297 │ 320 │ 37017 │ 304631 │ 390273 │ 46241 │ 558819 │ 95539 │ 1145988 │ 565846 │ 972673 │ 2443570 │ 2404869 │ 2238716 │ 3866062 │ 1273283 │
├─────────────┴────────┴────────┴────────┴────────┴────────┴────────┴─────────┴─────────┴─────────┴─────────┴──────────┴─────────┴─────────┴─────────┴─────────┴─────────┴──────────┴──────────┴─────────┴─────────┤
│ 18 rows 21 columns │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
Below are the methods of validation used.
SELECT VAL_METHOD,
COUNT(*)
FROM READ_PARQUET('*.pq')
GROUP BY 1
ORDER BY 2 DESC;
┌────────────┬──────────────┐
│ VAL_METHOD │ count_star() │
│ varchar │ int64 │
├────────────┼──────────────┤
│ Automated │ 99640705 │
│ Unverified │ 32168516 │
│ Manual │ 2731 │
└────────────┴──────────────┘