All The Places has a set of spiders and scrapers that extract location information from thousands of brands' websites.
Their GitHub repo is made up of 145K lines of Python with commits going back ten years. There have been a total of 162 contributors to date.
Their crawlers run weekly and the collected data is published shortly afterwards.
In this post, I'll examine their latest release.
My Workstation
I'm using a 5.7 GHz AMD Ryzen 9 9950X CPU. It has 16 cores and 32 threads and 1.2 MB of L1, 16 MB of L2 and 64 MB of L3 cache. It has a liquid cooler attached and is housed in a spacious, full-sized Cooler Master HAF 700 computer case.
The system has 96 GB of DDR5 RAM clocked at 4,800 MT/s and a 5th-generation, Crucial T700 4 TB NVMe M.2 SSD which can read at speeds up to 12,400 MB/s. There is a heatsink on the SSD to help keep its temperature down. This is my system's C drive.
The system is powered by a 1,200-watt, fully modular Corsair Power Supply and is sat on an ASRock X870E Nova 90 Motherboard.
I'm running Ubuntu 24 LTS via Microsoft's Ubuntu for Windows on Windows 11 Pro. In case you're wondering why I don't run a Linux-based desktop as my primary work environment, I'm still using an Nvidia GTX 1080 GPU which has better driver support on Windows and ArcGIS Pro only supports Windows natively.
Installing Prerequisites
I'll use Python 3.12.3 and a few other tools to help analyse the data in this post.
$ sudo add-apt-repository ppa:deadsnakes/ppa
$ sudo apt update
$ sudo apt install \
jq \
python3-pip \
python3.12-venv
I'll set up a Python Virtual Environment.
$ python3 -m venv ~/.atp
$ source ~/.atp/bin/activate
I'll use DuckDB v1.4.1, along with its H3, JSON, Lindel, Parquet and Spatial extensions, in this post.
$ cd ~
$ wget -c https://github.com/duckdb/duckdb/releases/download/v1.4.1/duckdb_cli-linux-amd64.zip
$ unzip -j duckdb_cli-linux-amd64.zip
$ chmod +x duckdb
$ ~/duckdb
INSTALL h3 FROM community;
INSTALL lindel FROM community;
INSTALL json;
INSTALL parquet;
INSTALL spatial;
I'll set up DuckDB to load every installed extension each time it launches.
$ vi ~/.duckdbrc
.timer on
.width 180
LOAD h3;
LOAD lindel;
LOAD json;
LOAD parquet;
LOAD spatial;
The maps in this post were rendered using QGIS version 3.44. QGIS is a desktop application that runs on Windows, macOS and Linux. The application has grown in popularity in recent years and has ~15M application launches from users all around the world each month.
I used QGIS' Tile+ plugin to add basemaps from Bing to the maps in this post.
Thousands of GeoJSON Files
The following will download a 1.4 GB ZIP file that contains 4,367 GeoJSON files totalling 14 GB when uncompressed.
$ mkdir -p ~/atp
$ cd ~/atp
$ wget -c https://alltheplaces-data.openaddresses.io/runs/2025-11-29-13-32-39/output.zip
$ unzip -j output.zip
The GeoJSON files are built by individual Python scripts which often can be country- or region-specific depending on the brand's online structure. Below are the files for Nando's.
$ ls -l nandos*
122771 .. nandos.geojson
16497 .. nandos_ae.geojson
6822 .. nandos_bh.geojson
16634 .. nandos_bw.geojson
555223 .. nandos_gb_ie.geojson
17450 .. nandos_in.geojson
3904 .. nandos_mu.geojson
39668 .. nandos_my.geojson
3663 .. nandos_om.geojson
10247 .. nandos_qa.geojson
3740 .. nandos_sg.geojson
0 .. nandos_us.geojson
308489 .. nandos_za.geojson
14091 .. nandos_zm.geojson
15739 .. nandos_zw.geojson
Roughly 500 of the 1,200+ Nando's locations are in either the UK or the Republic of Ireland. Below is an example record from their gb_ie file.
$ echo "FROM ST_READ('nandos_gb_ie.geojson')
LIMIT 1" \
| ~/duckdb -json \
| jq -S .
[
{
"@source_uri": "https://www.nandos.co.uk/restaurants/yate",
"@spider": "nandos_gb_ie",
"addr:city": "Yate, Gloucestershire",
"addr:country": "GB",
"addr:postcode": "BS37 4AS",
"addr:state": "England",
"addr:street_address": "Unit R2, Yate Shopping Centre, Link Rd",
"amenity": "restaurant",
"branch": "Yate",
"brand": "Nando's",
"brand:wikidata": "Q3472954",
"contact:facebook": "https://www.facebook.com/Nandos.UnitedKingdom",
"contact:twitter": "NandosUK",
"cuisine": "chicken;portuguese",
"geom": "POINT (-2.408309 51.539583)",
"id": "K8QmVBoxykViF1_30Vo-VcOrrto=",
"image": "https://www.nandos.co.uk/replatform/restaurants/img/default-restaurant-hero-background.png",
"name": "Nando's",
"nsi_id": "nandos-32ebee",
"opening_hours": "Mo-Su 11:30-22:00",
"payment:cash": "yes",
"payment:credit_cards": "yes",
"payment:debit_cards": "yes",
"phone": "+44 1454 312504",
"ref": "https://www.nandos.co.uk/restaurants/yate#restaurant",
"website": "https://www.nandos.co.uk/restaurants/yate"
}
]
Unique Brands
Below, I tried to get a rough idea of how many brands are represented in this release.
There were a few hundred brands with zero-byte GeoJSON files that I excluded. Many files ended with a single 2-digit country identifier; others, like the above Nando's example, had more than one. For the sake of this post's timebox, I accepted that margin of error.
$ python3
from glob import glob
import os
names = [x.split('.')[0]
for x in glob('*.geojson')
if os.path.getsize(x)]
brands = set()
for name in names:
# WIP: nandos_gb_ie won't get handled properly.
if len(name.split('_')[-1]) == 2:
brands.add('_'.join(name.split('_')[:1]))
else:
brands.add(name)
Without the zero-byte filter, there are 3,070 unique brands, but with the filter, there are 2,716.
There were over 900 open issues in the GitHub repository at the time of this writing. I didn't uncover many common themes between issues outside of Cloudflare becoming more popular among brands, while being unfriendly with their crawlers.
Perhaps it's possible that those empty GeoJSON files could have their datasets repopulated at some point down the line.
The Nando's GeoJSON file for the US in this release was zero bytes in size. The site itself is hosted directly from AWS. I suspect either the site has had a refresh or there was a network failure when the crawler ran.
I'm sure the crawler has functioned properly in the past. Publishing the last successful crawl's dataset instead of the latest, and potentially empty, dataset would be a good stopgap.
Location Metadata
Below, I'll count how many times each field name has been used across this release. There were seven GeoJSON files that Python was unable to parse, so they've been excluded.
$ python3
from glob import glob
import json
import os
key_counts = {}
for filename in glob('*.geojson'):
if os.path.getsize(filename) < 1:
continue
try:
for key in json.loads(open(filename).read())\
['features'][0]['properties'].keys():
if key not in key_counts:
key_counts[key] = 1
else:
key_counts[key] = key_counts[key] + 1
except json.JSONDecodeError:
print('Invalid JSON:', filename)
A total of 712 unique field names were seen in this release.
len(key_counts) # 712
Below are the top 25 field names.
sorted(key_counts, key=lambda x: x[1])[:25]
['name',
'camera:type',
'man_made',
'name:en',
'name:zh-Hans',
'name:zh-Hant',
'name:bg',
'name:mk',
'name:sq',
'cash_out',
'name:ja',
'natural',
'taxon:en',
'gambling',
'takeaway',
'map',
'camera:direction',
'payment:american_express',
'payment:apple_pay',
'payment:cash',
'payment:discover_card',
'payment:mastercard',
'payment:visa',
'fax',
'name:sr']
GeoJSON to Parquet
There already is a Parquet distribution, but it has been down since at least October. I'll run 24 concurrent processes that will convert the GeoJSON files into Parquet.
$ ls *.geojson \
| xargs -P24 \
-I% \
bash -c "
BASENAME=\`echo \"%\" | cut -f1 -d.\`
echo \"Building \$BASENAME.\"
echo \"COPY (FROM ST_READ('%'))
TO '\$BASENAME.parquet' (
FORMAT 'PARQUET',
CODEC 'ZSTD',
COMPRESSION_LEVEL 22,
ROW_GROUP_SIZE 15000);\" \
| ~/duckdb"
The following will merge the Parquet files into a single file.
$ ~/duckdb
COPY(
SELECT name,
geometry: geom,
bbox: {'xmin': ST_XMIN(ST_EXTENT(geom)),
'ymin': ST_YMIN(ST_EXTENT(geom)),
'xmax': ST_XMAX(ST_EXTENT(geom)),
'ymax': ST_YMAX(ST_EXTENT(geom))},
* EXCLUDE(name, geom)
FROM READ_PARQUET('*.parquet',
union_by_name=True,
filename=True)
WHERE ST_Y(ST_CENTROID(geom)) IS NOT NULL
ORDER BY HILBERT_ENCODE([ST_Y(ST_CENTROID(geom)),
ST_X(ST_CENTROID(geom))]::double[2])
) TO '~/atp.parquet' (
FORMAT 'PARQUET',
CODEC 'ZSTD',
COMPRESSION_LEVEL 22,
ROW_GROUP_SIZE 15000);
The resulting Parquet file is 1.4 GB and contains 19,059,494 records.
Locations Heatmap
Below is a heatmap of the locations in this release. The brighter hexagons have more locations.
$ ~/duckdb
CREATE OR REPLACE TABLE h3_3_stats AS
SELECT h3_3: H3_LATLNG_TO_CELL(
bbox.ymin,
bbox.xmin,
3),
num_locations: COUNT(*)
FROM '~/atp.parquet'
GROUP BY 1;
COPY (
SELECT geometry: ST_ASWKB(H3_CELL_TO_BOUNDARY_WKT(h3_3)::geometry),
num_locations
FROM h3_3_stats
WHERE ST_XMIN(geometry::geometry) BETWEEN -179 AND 179
AND ST_XMAX(geometry::geometry) BETWEEN -179 AND 179
) TO '~/atp.h3_3_stats.parquet' (
FORMAT 'PARQUET',
CODEC 'ZSTD',
COMPRESSION_LEVEL 22,
ROW_GROUP_SIZE 15000);

There are a lot of locations located in bodies of water and all across Antarctica.
These are the most common brand names.
SELECT COUNT(*),
name
FROM '~/atp.parquet'
WHERE LENGTH(name)
GROUP BY 2
ORDER BY 1 DESC
LIMIT 40;
┌──────────────┬──────────────────────────────────┐
│ count_star() │ name │
│ int64 │ varchar │
├──────────────┼──────────────────────────────────┤
│ 68227 │ Wildberries │
│ 55171 │ サントリー │
│ 39731 │ Shell │
│ 26767 │ 7-Eleven │
│ 24920 │ Coinstar │
│ 23271 │ McDonald's │
│ 21495 │ Starbucks │
│ 20504 │ Dollar General │
│ 20380 │ Punjab National Bank │
│ 19519 │ FedEx Drop Box │
│ 13760 │ Walgreens │
│ 13660 │ HDFC Bank ATM │
│ 13346 │ Burger King │
│ 13050 │ Circle K │
│ 13028 │ Chevron │
│ 13006 │ KFC │
│ 12670 │ FedEx OnSite │
│ 12279 │ Żabka │
│ 12074 │ InPost │
│ 11652 │ TotalEnergies │
│ 10993 │ HDFC Bank │
│ 10772 │ Aldi │
│ 10612 │ Şok │
│ 9993 │ BP │
│ 9993 │ Lidl │
│ 9435 │ Dunkin' │
│ 9292 │ Dollar Tree │
│ 9080 │ Bitcoin Depot │
│ 8568 │ ICICI Bank │
│ 8424 │ Taco Bell │
│ 8395 │ 星巴克 │
│ 8193 │ Bank of Baroda │
│ 7751 │ Verizon │
│ 7700 │ CVS Pharmacy │
│ 7677 │ Subway │
│ 7577 │ T-Mobile │
│ 7403 │ AutoZone │
│ 7367 │ H&R Block Tax Preparation Office │
│ 7339 │ Family Dollar │
│ 7318 │ Blue Rhino │
├──────────────┴──────────────────────────────────┤
│ 40 rows 2 columns │
└─────────────────────────────────────────────────┘
There are 2.36M unique strings in the name column. I was expecting this number to be much close to the ~3-4K brands there are scrapers for.
SELECT COUNT(DISTINCT name)
FROM '~/atp.parquet'; -- 2,358,505
I'll build a bounding box that surrounds each brand's locations in each country they're represented in.
COPY (
SELECT name,
country: "addr:country",
geometry: {
'min_x': MIN(ST_X(ST_CENTROID(geometry))),
'min_y': MIN(ST_Y(ST_CENTROID(geometry))),
'max_x': MAX(ST_X(ST_CENTROID(geometry))),
'max_y': MAX(ST_Y(ST_CENTROID(geometry)))}::BOX_2D::GEOMETRY
FROM '~/atp.parquet'
GROUP BY 1, 2
) TO '~/atp.extent_per_country.parquet' (
FORMAT 'PARQUET',
CODEC 'ZSTD',
COMPRESSION_LEVEL 22,
ROW_GROUP_SIZE 15000);
Below are the countries with Nando's locations in this release. Note, the US locations are missing.
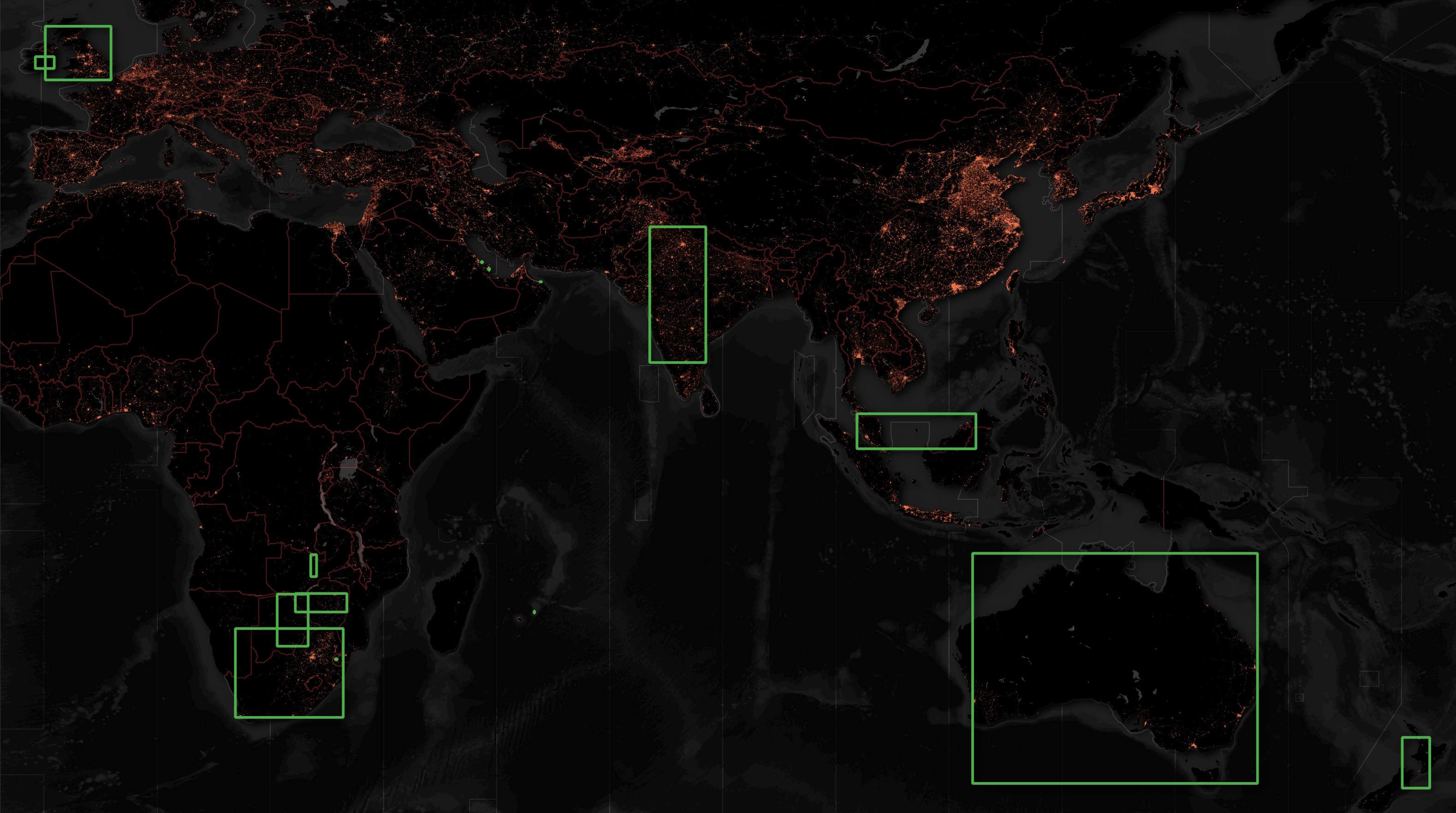
Below are the Starbucks locations. I've been to several Starbucks locations in the UAE and Thailand that aren't present in this release. After I made this map, I found an additional 8,395 Starbucks locations with the the Chinese name "星巴克".
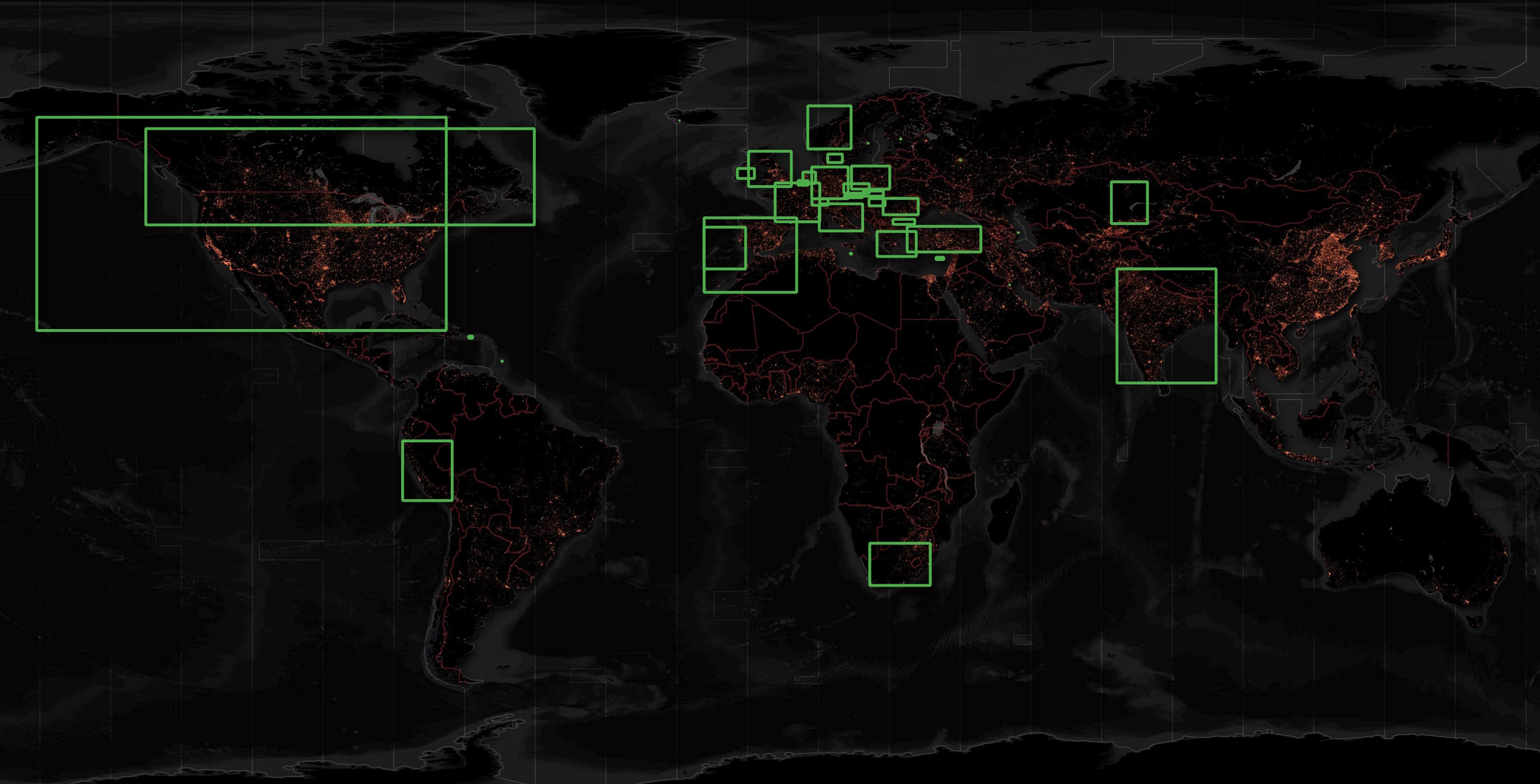
For some reason, only 11 countries have at least one McDonalds restaurant in this release.
SELECT COUNT(DISTINCT "addr:country")
FROM '~/atp.parquet'
WHERE name LIKE '%McDonalds%'; -- 11
There are 44K McDonald's restaurants in the world but this release only lists 23,271 of them.
Spot Checking
Despite wide IKEA coverage, Estonia's Flagship store is missing.
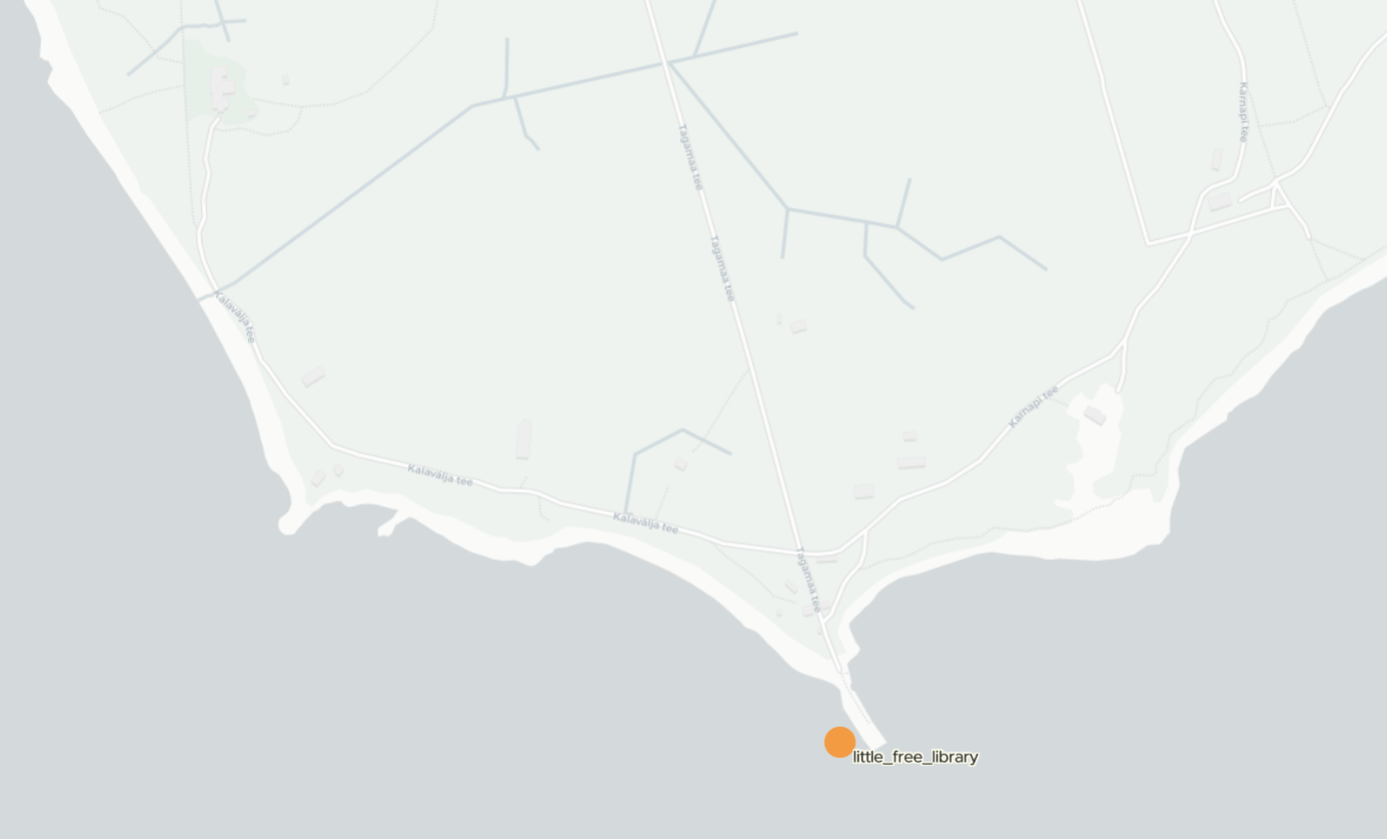
There is a Romanian Library just off the coast of one of Estonia's Islands.
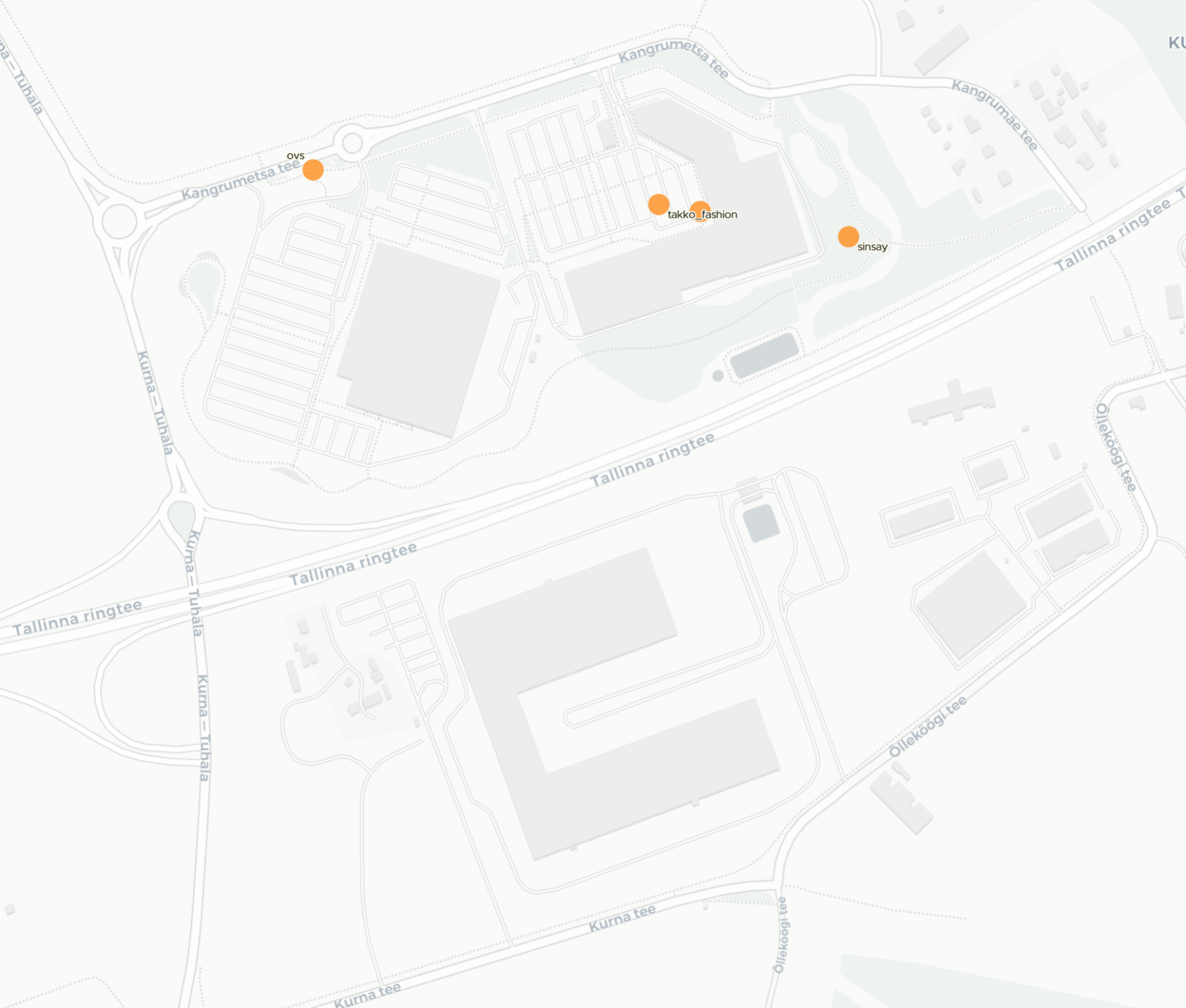
A Finnish fast food chain placed its restaurant outside of an Estonian shopping centre rather than inside.
