In this post, I'm going to see how fast ClickHouse 24.3.1.1234 can run the 1.1 billion taxi rides benchmark. This dataset is made up of 1.1 billion taxi trips conducted in New York City between 2009 and 2015. This is the same dataset I've used to benchmark Amazon Athena, BigQuery, BrytlytDB, DuckDB, Elasticsearch, EMR, Hydrolix, kdb+/q, MapD / OmniSci / HEAVY.AI, PostgreSQL, Redshift and Vertica. I have a single-page summary of all these benchmarks for comparison.
My Workstation
For this benchmark, I'm using a 6 GHz Intel Core i9-14900K CPU. It has 8 performance cores and 16 efficiency cores with a total of 32 threads and 32 MB of L2 cache. It has a liquid cooler attached and is housed in a spacious, full-sized, Cooler Master HAF 700 computer case. I've come across videos on YouTube where people have managed to overclock the i9-14900KF to 9.1 GHz.
The system has 48 GB of DDR5 RAM clocked at 5,200 MHz and a 5th-generation, Crucial T700 4 TB NVMe M.2 SSD which can read at speeds up to 12,400 MB/s. There is a heatsink on the SSD to help keep its temperature down. This is my system's C drive.
There is also a 2 TB SSD connected via a SATA interface which contains the original taxi rides dataset. This drive peaks around 5-600 MB/s. This is my system's D drive.
The system is powered by a 1,200-watt, fully modular, Corsair Power Supply and is sat on an ASRock Z790 Pro RS Motherboard.
I'm running Ubuntu 22 LTS via Microsoft's Ubuntu for Windows on Windows 11 Pro. In case you're wondering why I don't run a Linux-based desktop as my primary work environment, I'm still using an Nvidia GTX 1080 GPU which has better driver support on Windows and I use ArcGIS Pro from time to time which only supports Windows natively.
ClickHouse Up & Running
Two years ago, ClickHouse began distributing as a single binary that can be downloaded with a single command. The following downloaded version 24.3.1.1234 to my home folder.
$ cd ~
$ curl https://clickhouse.com/ | sh
Importing 1.1 Billion Trips
The dataset I'll be using is a data dump I've produced of 1.1 billion taxi trips conducted in New York City over six years. The raw dataset lives as 56 GZIP-compressed CSV files that are 104 GB when compressed and need 500 GB of space when decompressed. The Billion Taxi Rides in Redshift blog post goes into detail regarding how I put this dataset together and describes the columns it contains in further detail.
I'll read the source data from /mnt/d/taxi which is on the SATA-connected SSD.
ClickHouse can both host data as a server and/or run in stand-alone 'local' mode. When run in local mode, will create a temporary working folder on the primary drive, the 5th-generation NVMe drive in this case, to store its data.
Below I'll launch ClickHouse in local mode and import the taxi ride dataset off of the SATA-backed SSD.
$ cd /mnt/d/taxi
$ ~/clickhouse
CREATE TABLE trips (
trip_id INT,
vendor_id VARCHAR(3),
pickup_datetime TIMESTAMP,
dropoff_datetime TIMESTAMP,
store_and_fwd_flag VARCHAR(1),
rate_code_id SMALLINT,
pickup_longitude DECIMAL(18,14),
pickup_latitude DECIMAL(18,14),
dropoff_longitude DECIMAL(18,14),
dropoff_latitude DECIMAL(18,14),
passenger_count SMALLINT,
trip_distance DECIMAL(18,6),
fare_amount DECIMAL(18,6),
extra DECIMAL(18,6),
mta_tax DECIMAL(18,6),
tip_amount DECIMAL(18,6),
tolls_amount DECIMAL(18,6),
ehail_fee DECIMAL(18,6),
improvement_surcharge DECIMAL(18,6),
total_amount DECIMAL(18,6),
payment_type VARCHAR(3),
trip_type SMALLINT,
pickup VARCHAR(50),
dropoff VARCHAR(50),
cab_type VARCHAR(6),
precipitation SMALLINT,
snow_depth SMALLINT,
snowfall SMALLINT,
max_temperature SMALLINT,
min_temperature SMALLINT,
average_wind_speed SMALLINT,
pickup_nyct2010_gid SMALLINT,
pickup_ctlabel VARCHAR(10),
pickup_borocode SMALLINT,
pickup_boroname VARCHAR(13),
pickup_ct2010 VARCHAR(6),
pickup_boroct2010 VARCHAR(7),
pickup_cdeligibil VARCHAR(1),
pickup_ntacode VARCHAR(4),
pickup_ntaname VARCHAR(56),
pickup_puma VARCHAR(4),
dropoff_nyct2010_gid SMALLINT,
dropoff_ctlabel VARCHAR(10),
dropoff_borocode SMALLINT,
dropoff_boroname VARCHAR(13),
dropoff_ct2010 VARCHAR(6),
dropoff_boroct2010 VARCHAR(7),
dropoff_cdeligibil VARCHAR(1),
dropoff_ntacode VARCHAR(4),
dropoff_ntaname VARCHAR(56),
dropoff_puma VARCHAR(4)
) ENGINE = Log;
INSERT INTO trips
SELECT *
FROM file('trips_*.csv.gz', CSV);
The above completed in 1 hour, 45 minutes and 58 seconds. The CPU sat at less than 10% utilisation during the import. RAM consumption started out at 13.5 GB and grew to 22 GB by the time the import was 20% complete. The SATA-backed SSD read at rates of 10-25 MB/s and there were occasional bursts of writes to the 5th-generation SSD at 500 MB/s.
Below are a few of the temporary files ClickHouse used to store the dataset in its internal format.
$ sudo lsof -OnP \
| grep -o '/tmp/clickhouse-local.*' \
| head
/tmp/clickhouse-local-427434-1710839151-17010793528146335445/data/default/trips/trip_id.bin
/tmp/clickhouse-local-427434-1710839151-17010793528146335445/data/default/trips/vendor_id.bin
/tmp/clickhouse-local-427434-1710839151-17010793528146335445/data/default/trips/pickup_datetime.bin
/tmp/clickhouse-local-427434-1710839151-17010793528146335445/data/default/trips/dropoff_datetime.bin
/tmp/clickhouse-local-427434-1710839151-17010793528146335445/data/default/trips/store_and_fwd_flag.bin
/tmp/clickhouse-local-427434-1710839151-17010793528146335445/data/default/trips/rate_code_id.bin
/tmp/clickhouse-local-427434-1710839151-17010793528146335445/data/default/trips/pickup_longitude.bin
/tmp/clickhouse-local-427434-1710839151-17010793528146335445/data/default/trips/pickup_latitude.bin
/tmp/clickhouse-local-427434-1710839151-17010793528146335445/data/default/trips/dropoff_longitude.bin
/tmp/clickhouse-local-427434-1710839151-17010793528146335445/data/default/trips/dropoff_latitude.bin
The dataset needs to be imported initially in row-oriented form. Once imported, a second, columnar-oriented table, which is more suited for analytics, can be built. The storage engine behind this table is called 'MergeTree'.
CREATE TABLE trips_mergetree
ENGINE MergeTree()
ORDER BY (pickup_date, pickup_datetime)
SETTINGS index_granularity=8192
AS SELECT
trip_id,
CAST(vendor_id AS Enum8('1' = 1,
'2' = 2,
'CMT' = 3,
'VTS' = 4,
'DDS' = 5,
'B02512' = 10,
'B02598' = 11,
'B02617' = 12,
'B02682' = 13,
'B02764' = 14)) AS vendor_id,
toDate(pickup_datetime) AS pickup_date,
ifNull(pickup_datetime, toDateTime(0)) AS pickup_datetime,
toDate(dropoff_datetime) AS dropoff_date,
ifNull(dropoff_datetime, toDateTime(0)) AS dropoff_datetime,
assumeNotNull(store_and_fwd_flag) AS store_and_fwd_flag,
assumeNotNull(rate_code_id) AS rate_code_id,
assumeNotNull(pickup_longitude) AS pickup_longitude,
assumeNotNull(pickup_latitude) AS pickup_latitude,
assumeNotNull(dropoff_longitude) AS dropoff_longitude,
assumeNotNull(dropoff_latitude) AS dropoff_latitude,
assumeNotNull(passenger_count) AS passenger_count,
assumeNotNull(trip_distance) AS trip_distance,
assumeNotNull(fare_amount) AS fare_amount,
assumeNotNull(extra) AS extra,
assumeNotNull(mta_tax) AS mta_tax,
assumeNotNull(tip_amount) AS tip_amount,
assumeNotNull(tolls_amount) AS tolls_amount,
assumeNotNull(ehail_fee) AS ehail_fee,
assumeNotNull(improvement_surcharge) AS improvement_surcharge,
assumeNotNull(total_amount) AS total_amount,
assumeNotNull(payment_type) AS payment_type_,
assumeNotNull(trip_type) AS trip_type,
CAST(assumeNotNull(cab_type)
AS Enum8('yellow' = 1, 'green' = 2))
AS cab_type,
pickup AS pickup,
pickup AS dropoff,
precipitation AS precipitation,
snow_depth AS snow_depth,
snowfall AS snowfall,
max_temperature AS max_temperature,
min_temperature AS min_temperature,
average_wind_speed AS average_wind_speed,
pickup_nyct2010_gid AS pickup_nyct2010_gid,
pickup_ctlabel AS pickup_ctlabel,
pickup_borocode AS pickup_borocode,
pickup_boroname AS pickup_boroname,
pickup_ct2010 AS pickup_ct2010,
pickup_boroct2010 AS pickup_boroct2010,
pickup_cdeligibil AS pickup_cdeligibil,
pickup_ntacode AS pickup_ntacode,
pickup_ntaname AS pickup_ntaname,
pickup_puma AS pickup_puma,
dropoff_nyct2010_gid AS dropoff_nyct2010_gid,
dropoff_ctlabel AS dropoff_ctlabel,
dropoff_borocode AS dropoff_borocode,
dropoff_boroname AS dropoff_boroname,
dropoff_ct2010 AS dropoff_ct2010,
dropoff_boroct2010 AS dropoff_boroct2010,
dropoff_cdeligibil AS dropoff_cdeligibil,
dropoff_ntacode AS dropoff_ntacode,
dropoff_ntaname AS dropoff_ntaname,
dropoff_puma AS dropoff_puma
FROM trips;
The MergeTree table was built in 27 minutes and 8 seconds. RAM consumption started out at 21.3 GB and topped out at just under 24 GB. The CPU utilisation was under 25% during most of the import with ~10 cores intermittently coming under heavy load. Below is a screenshot of the Windows' Task Manager during this operation.
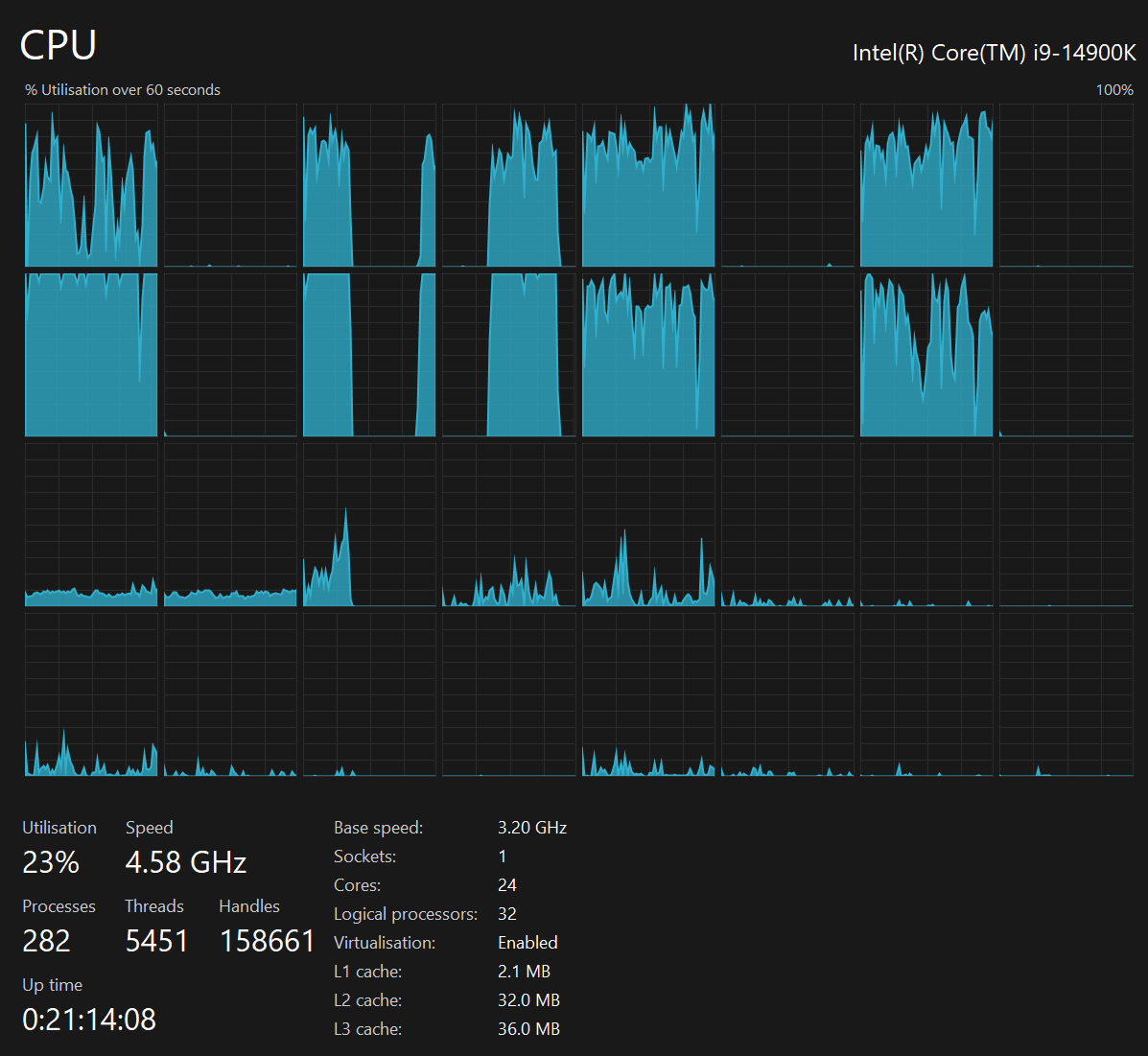
The 5th-generation SSD read at 80-200 MB/s with write bursts every 20-30 seconds of 600 MB/s - 1 GB/s. Below is a screenshot from the Windows' Task Manager during this operation.
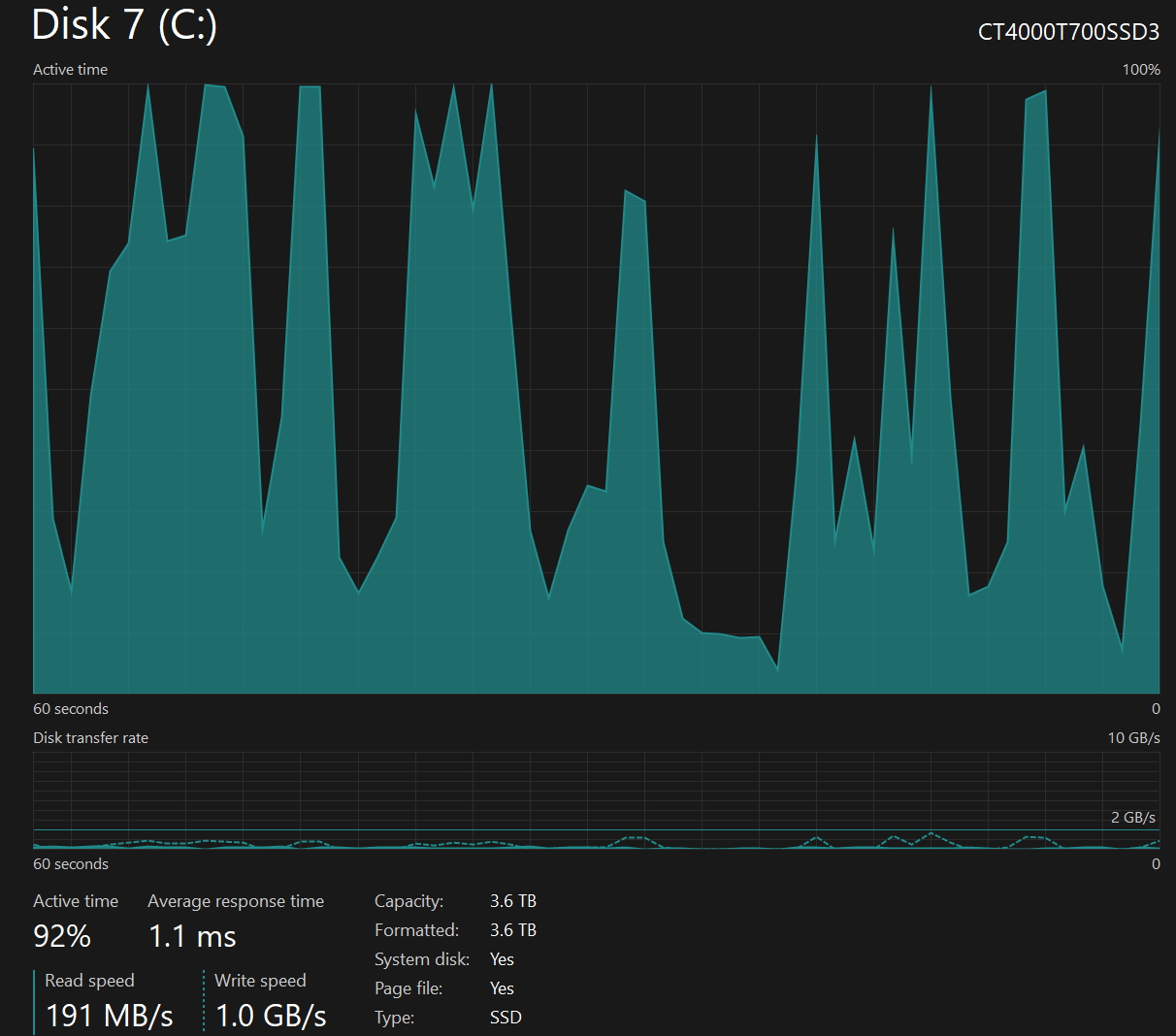
Benchmark
The following were the fastest times I saw after running each query multiple times on the MergeTree table.
The following completed in 0.088 seconds.
SELECT cab_type,
count(*)
FROM trips_mergetree
GROUP BY cab_type;
The following completed in 0.51 seconds.
SELECT passenger_count,
avg(total_amount)
FROM trips_mergetree
GROUP BY passenger_count;
The following completed in 0.424 seconds.
SELECT passenger_count,
toYear(pickup_date) AS year,
count(*)
FROM trips_mergetree
GROUP BY passenger_count,
year;
The following completed in 1.257 seconds.
SELECT passenger_count,
toYear(pickup_date) AS year,
round(trip_distance) AS distance,
count(*)
FROM trips_mergetree
GROUP BY passenger_count,
year,
distance
ORDER BY year,
count(*) DESC;