DoubleCloud is a newly-launched managed database provider. With a headcount of 50, they have development and sales offices in Berlin, Prague and Tel Aviv. Further office openings in the US, UK and France are expected in the next few months. DoubleCloud lets you run ClickHouse and Kafka on your own Cloud account. They provide a UI to set up and scale while software and operating system updates are handled automatically.
DoubleCloud also offers consulting services to help migrate existing workloads to their offering. Earlier this year, I teamed up with them to help Paris-based Enterprise SEO provider Botify understand what it would take to move their 5 PB data warehouse from BigQuery to DoubleCloud.
The key to being able to improve Botify's workload performance while saving ~5x on storage costs was the S3 storage engine for ClickHouse. This allows storage to scale automatically, minimises maintenance and typically only incurs a 2-3x performance penalty over DoubleCloud's EBS-based storage option.
The S3 support in DoubleCloud includes a Hybrid storage engine. When you launch a cluster, an S3 bucket is set up automatically. When your cluster detects it's running low on local storage space it'll automatically transfer your data off to S3. This migration won't require any existing queries to be rewritten. Communication with S3 is optimised with a caching layer which can speed up queries by 4.5x in some cases once the cache has been warmed up.
DoubleCloud's support has 16 hours a day of coverage year-round. The firm also hosts multi-day training workshops. Active contributors to the ClickHouse codebase staff their 3rd line of support. These engineers are experts in both C++ and database and operating system architecture.
DoubleCloud support per-second billing and its pricing model sets a ceiling on spend rather than a floor. In the past, I've seen clients hit with sticker shock after simple scripts hit their pay-per-query database providers more often than expected. With a price ceiling, predicting spend is much easier.
In this post, I'm going to see how fast DoubleCloud can run the 1.1 billion taxi rides benchmark. This dataset is made up of 1.1 billion taxi trips conducted in New York City between 2009 and 2015. This is the same dataset I've used to benchmark Amazon Athena, BigQuery, BrytlytDB, Elasticsearch, EMR, Hydrolix, kdb+/q, OmniSci, PostgreSQL, Redshift and Vertica. I have a single-page summary of all these benchmarks for comparison.
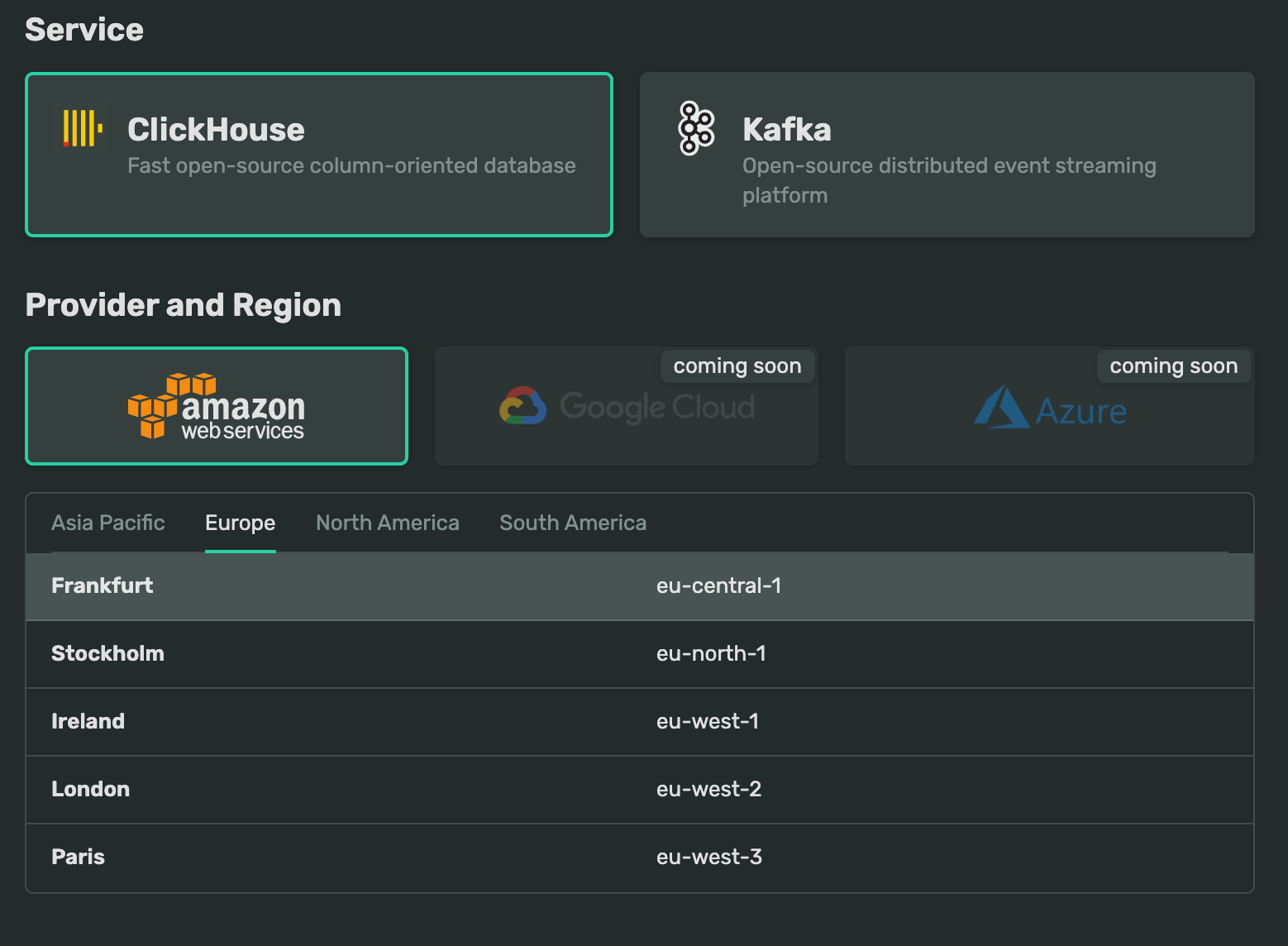
DoubleCloud, Up & Running
DoubleCloud offers a UI for launching ClickHouse. For this post, I'll launch an s1-c32-m128 instance on AWS' eu-central-1 region in Frankfurt, Germany. This instance has 32 cores, 128 GB of RAM, 512 GB of storage and runs version 22.8 of DoubleCloud's ClickHouse release. If this cluster is left running for a month it would cost $2,516.35 before any sales taxes.
I'll install ClickHouse's client locally on my system and use it to connect to the newly launched instance.
$ curl https://clickhouse.com/ | sh
$ ./clickhouse client \
--host ****.at.double.cloud \
--port 9440 \
--secure \
--user admin \
--password ****
Importing 1.1 Billion Taxi Trips
The dataset I'll be using is a data dump I've produced of 1.1 billion taxi trips conducted in New York City over six years. The raw dataset lives as 56 GZIP-compressed CSV files that are 104 GB when compressed and need 500 GB of space when decompressed. The Billion Taxi Rides in Redshift blog post goes into detail regarding how I put this dataset together and describes the columns it contains in further detail.
I'll first create a new row-based table.
CREATE TABLE ebs.trips (
trip_id UInt32,
vendor_id String,
pickup_datetime DateTime,
dropoff_datetime Nullable(DateTime),
store_and_fwd_flag Nullable(FixedString(1)),
rate_code_id Nullable(UInt8),
pickup_longitude Nullable(Float64),
pickup_latitude Nullable(Float64),
dropoff_longitude Nullable(Float64),
dropoff_latitude Nullable(Float64),
passenger_count Nullable(UInt8),
trip_distance Nullable(Float64),
fare_amount Nullable(Float32),
extra Nullable(Float32),
mta_tax Nullable(Float32),
tip_amount Nullable(Float32),
tolls_amount Nullable(Float32),
ehail_fee Nullable(Float32),
improvement_surcharge Nullable(Float32),
total_amount Nullable(Float32),
payment_type Nullable(String),
trip_type Nullable(UInt8),
pickup Nullable(String),
dropoff Nullable(String),
cab_type Nullable(String),
precipitation Nullable(Int8),
snow_depth Nullable(Int8),
snowfall Nullable(Int8),
max_temperature Nullable(Int8),
min_temperature Nullable(Int8),
average_wind_speed Nullable(Int8),
pickup_nyct2010_gid Nullable(Int8),
pickup_ctlabel Nullable(String),
pickup_borocode Nullable(Int8),
pickup_boroname Nullable(String),
pickup_ct2010 Nullable(String),
pickup_boroct2010 Nullable(String),
pickup_cdeligibil Nullable(FixedString(1)),
pickup_ntacode Nullable(String),
pickup_ntaname Nullable(String),
pickup_puma Nullable(String),
dropoff_nyct2010_gid Nullable(UInt8),
dropoff_ctlabel Nullable(String),
dropoff_borocode Nullable(UInt8),
dropoff_boroname Nullable(String),
dropoff_ct2010 Nullable(String),
dropoff_boroct2010 Nullable(String),
dropoff_cdeligibil Nullable(String),
dropoff_ntacode Nullable(String),
dropoff_ntaname Nullable(String),
dropoff_puma Nullable(String)
) ENGINE = Log;
I'll then import the dataset from S3 using 56 threads.
INSERT INTO ebs.trips
SELECT *
FROM s3('https://s3.eu-central-1.amazonaws.com/<bucket>/csv/trips*.csv.gz',
'<access-key>',
'<secret-access-key>',
'CSV',
'
trip_id UInt32,
vendor_id String,
pickup_datetime DateTime,
dropoff_datetime Nullable(DateTime),
store_and_fwd_flag Nullable(FixedString(1)),
rate_code_id Nullable(UInt8),
pickup_longitude Nullable(Float64),
pickup_latitude Nullable(Float64),
dropoff_longitude Nullable(Float64),
dropoff_latitude Nullable(Float64),
passenger_count Nullable(UInt8),
trip_distance Nullable(Float64),
fare_amount Nullable(Float32),
extra Nullable(Float32),
mta_tax Nullable(Float32),
tip_amount Nullable(Float32),
tolls_amount Nullable(Float32),
ehail_fee Nullable(Float32),
improvement_surcharge Nullable(Float32),
total_amount Nullable(Float32),
payment_type Nullable(String),
trip_type Nullable(UInt8),
pickup Nullable(String),
dropoff Nullable(String),
cab_type Nullable(String),
precipitation Nullable(Int8),
snow_depth Nullable(Int8),
snowfall Nullable(Int8),
max_temperature Nullable(Int8),
min_temperature Nullable(Int8),
average_wind_speed Nullable(Int8),
pickup_nyct2010_gid Nullable(Int8),
pickup_ctlabel Nullable(String),
pickup_borocode Nullable(Int8),
pickup_boroname Nullable(String),
pickup_ct2010 Nullable(String),
pickup_boroct2010 Nullable(String),
pickup_cdeligibil Nullable(FixedString(1)),
pickup_ntacode Nullable(String),
pickup_ntaname Nullable(String),
pickup_puma Nullable(String),
dropoff_nyct2010_gid Nullable(UInt8),
dropoff_ctlabel Nullable(String),
dropoff_borocode Nullable(UInt8),
dropoff_boroname Nullable(String),
dropoff_ct2010 Nullable(String),
dropoff_boroct2010 Nullable(String),
dropoff_cdeligibil Nullable(String),
dropoff_ntacode Nullable(String),
dropoff_ntaname Nullable(String),
dropoff_puma Nullable(String)',
'gzip')
SETTINGS max_threads=56,
max_insert_threads=56;
The above finished in 29 minutes and 25 seconds. The resulting table is stored on the instance's EBS volume and is 144.88 GB in size. Below I'll convert the data into an optimised column-based table.
SET max_insert_threads=2;
CREATE TABLE ebs.trips_mergetree
ENGINE = MergeTree()
PARTITION BY toYYYYMM(pickup_date)
ORDER BY (pickup_datetime)
AS SELECT
trip_id,
CAST(vendor_id AS Enum8('1' = 1,
'2' = 2,
'CMT' = 3,
'VTS' = 4,
'DDS' = 5,
'B02512' = 10,
'B02598' = 11,
'B02617' = 12,
'B02682' = 13,
'B02764' = 14)) AS vendor_id,
toDate(pickup_datetime) AS pickup_date,
ifNull(pickup_datetime, toDateTime(0)) AS pickup_datetime,
toDate(dropoff_datetime) AS dropoff_date,
ifNull(dropoff_datetime, toDateTime(0)) AS dropoff_datetime,
assumeNotNull(store_and_fwd_flag) AS store_and_fwd_flag,
assumeNotNull(rate_code_id) AS rate_code_id,
assumeNotNull(pickup_longitude) AS pickup_longitude,
assumeNotNull(pickup_latitude) AS pickup_latitude,
assumeNotNull(dropoff_longitude) AS dropoff_longitude,
assumeNotNull(dropoff_latitude) AS dropoff_latitude,
assumeNotNull(passenger_count) AS passenger_count,
assumeNotNull(trip_distance) AS trip_distance,
assumeNotNull(fare_amount) AS fare_amount,
assumeNotNull(extra) AS extra,
assumeNotNull(mta_tax) AS mta_tax,
assumeNotNull(tip_amount) AS tip_amount,
assumeNotNull(tolls_amount) AS tolls_amount,
assumeNotNull(ehail_fee) AS ehail_fee,
assumeNotNull(improvement_surcharge) AS improvement_surcharge,
assumeNotNull(total_amount) AS total_amount,
assumeNotNull(payment_type) AS payment_type_,
assumeNotNull(trip_type) AS trip_type,
pickup AS pickup,
pickup AS dropoff,
CAST(assumeNotNull(cab_type)
AS Enum8('yellow' = 1, 'green' = 2))
AS cab_type,
precipitation AS precipitation,
snow_depth AS snow_depth,
snowfall AS snowfall,
max_temperature AS max_temperature,
min_temperature AS min_temperature,
average_wind_speed AS average_wind_speed,
pickup_nyct2010_gid AS pickup_nyct2010_gid,
pickup_ctlabel AS pickup_ctlabel,
pickup_borocode AS pickup_borocode,
pickup_boroname AS pickup_boroname,
pickup_ct2010 AS pickup_ct2010,
pickup_boroct2010 AS pickup_boroct2010,
pickup_cdeligibil AS pickup_cdeligibil,
pickup_ntacode AS pickup_ntacode,
pickup_ntaname AS pickup_ntaname,
pickup_puma AS pickup_puma,
dropoff_nyct2010_gid AS dropoff_nyct2010_gid,
dropoff_ctlabel AS dropoff_ctlabel,
dropoff_borocode AS dropoff_borocode,
dropoff_boroname AS dropoff_boroname,
dropoff_ct2010 AS dropoff_ct2010,
dropoff_boroct2010 AS dropoff_boroct2010,
dropoff_cdeligibil AS dropoff_cdeligibil,
dropoff_ntacode AS dropoff_ntacode,
dropoff_ntaname AS dropoff_ntaname,
dropoff_puma AS dropoff_puma
FROM ebs.trips;
The above finished in 50 minutes and 43 seconds and takes up 98.3 GB of EBS storage.
The following is an optional step but it saved 593 MB of space and improved query times by 7-10%. It took 51 minutes and 50 seconds to complete.
OPTIMIZE TABLE ebs.trips_mergetree FINAL;
Benchmarking DoubleCloud
The following were the fastest times I saw after running each query multiple times.
The following finished in 0.347 seconds.
SELECT cab_type, count(*)
FROM ebs.trips_mergetree
GROUP BY cab_type;
The following finished in 1.1 seconds.
SELECT passenger_count,
avg(total_amount)
FROM ebs.trips_mergetree
GROUP BY passenger_count;
The following finished in 1.389 seconds.
SELECT passenger_count,
toYear(pickup_date) AS year,
count(*)
FROM ebs.trips_mergetree
GROUP BY passenger_count,
year;
The following finished in 2.935 seconds.
SELECT passenger_count,
toYear(pickup_date) AS year,
round(trip_distance) AS distance,
count(*)
FROM ebs.trips_mergetree
GROUP BY passenger_count,
year,
distance
ORDER BY year,
count(*) DESC;
Closing Thoughts
The first query's time is the fastest I've seen among any of the Cloud-exclusive offerings I've run benchmarks on. It's great to see these times without the need for any sort of complex tuning or extensive hardware planning.
Hybrid storage is a real game changer. Often clients want to keep an entire dataset, if not several, accessible via a single database. These datasets can stretch back years but often only the past month or two is being actively queried. Provisioning 512 GB of local storage for a 5 TB dataset means you can keep the EBS costs low, let DoubleCloud figure out which records should live on S3 and which should be cached while enjoying ClickHouse's incredible performance.
The per-second billing is also handy. I have clients that have modest datasets but occasionally bring in a large dataset for a one-off analysis piece. Being able to spin up a cluster for a few hours if not minutes and get the answers out of the data while not paying for a second more than needed is fantastic.